CXL 3.1 소개와 스토리지
by 박주형 (jhpark@gluesys.com)
지난 번 <PCIe를 대체할 인터커넥트 표준 기술, CXL> 포스트에서 CXL(Compute Express Link)에 대해 2.0 버전을 기준으로 내용을 다룬 바 있었습니다. 그로부터 약 2년이 지난 현재(2024년 1월), CXL은 기술적인 성숙도 뿐만 아니라, 인터커넥트 표준으로써의 위상도 많이 높아졌습니다.
현재 CPU, GPU, DPU 등 프로세서는 각각 구분된 메모리 공간을 가지고 있고, 프로세서 간 데이터 공유를 위해 메모리 간 데이터 이동 및 복사를 PCIe를 통해 수행합니다. PCIe는 고속 인터페이스이기는 하나, 대규모 데이터 전송 시 프로토콜 처리 과정에서 오버헤드가 발생하며, 메모리 채널에 비해 매우 느립니다. 게다가 프로세서 간에 메모리를 공유하는 경우, 한쪽 메모리에서 데이터가 변경되면 다른 쪽 메모리의 데이터와 일관성 문제가 발생하게 됩니다. CXL은 이러한 프로세서 메모리 간 장벽을 허물고, 공유 메모리 풀을 형성해 프로세서가 거대한 메모리 자원을 저지연으로 접근하게 하는 것이 목적입니다. 또한, 프로세서에서 메모리 풀 접근 시 이동 및 복사 과정이 필요 없기 때문에 메모리 간 일관성을 유지할 수 있습니다. CXL은 데이터센터와 같은 대규모 데이터를 운용하고 처리하는 환경에서 메모리 자원의 낭비 없이 활용할 수 있고, 기존과는 달리 애플리케이션에 매우 큰 메모리를 할당할 수 있습니다. 자세한 내용은 이전 포스트 <PCIe를 대체할 인터커넥트 표준 기술, CXL> 를 참고 부탁드립니다.
지난 CXL 2.0 버전에서는 CXL 스위치의 등장과 퍼시스턴트 메모리 지원, CXL IDE를 통한 보안 강화가 주 내용이였습니다. 그리고 2022년 8월에 3.0 버전, 작년 11월에 3.1 버전을 공개하면서 새로운 아키텍처와 기능들을 발표했습니다. 많이 늦기는 했지만 이번 포스트에서는 지난 CXL 3.0 버전부터 어떤 내용들이 업데이트되었는지 알아보고자 합니다.
CXL 3.1까지의 주요 변경사항
이번 CXL 3.0과 3.1 버전은 전세계 주요 산업 관계자들과 커뮤니티의 기여에 힘입어 매우 많은 구조와 기능들이 업데이트되었습니다. CXL 3.0부터는 PCIe 6.0을 지원하게 되면서 패브릭 기능, 구조 및 보안 등을 개선했고, 클러스터 환경에서의 캐시 일관성과 메모리 풀 공유 기능을 강화하는 등 CXL의 성능과 활용 범위가 다시 한번 확장되었습니다. 주요 업데이트 내용은 다음과 같습니다.
-
대역폭 2배 향상: CXL 2.0까지는 PCIe 5.0을 지원했는데, CXL 3.0부터는 PCIe 6.0을 지원하게 되었습니다. 이로 인해 기존 CXL 2.0 대역폭의 2배인 최대 64GT/s까지 제공해 PCIe x16 링크 기준 이론상 최대 256GB/s까지 성능을 제공할 수 있게 되었습니다.
-
PCIe 6.0 지원에 따른 기능 개선: CXL 3.0부터는 PCIe 6.0에서 제공하는 4레벨 펄스 진폭 변조(PAM-4) 시그널링과 경량 FEC(Forward Error Correction), CRC(Cyclic Redundancy Check)를 그대로 활용해 낮은 지연시간과 복잡도, 전송 에러 방지를 구현하고자 했고, 256 바이트 FLIT(Flow Control Unit) 단위로 데이터를 전송합니다.
-
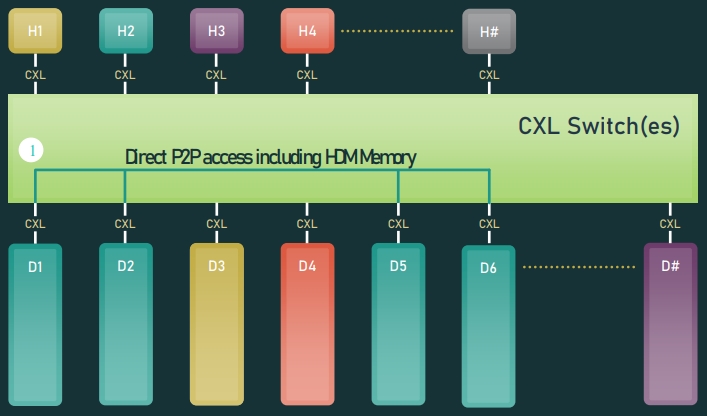
캐시 일관성 강화: CXL 3.0 부터는 CXL 메모리 장치에서 BISnp(Back-Invalidate Snoop)로 호스트의 캐시 상태를 변경시켜 다중 호스트 접근 환경에서 HDM1의 캐시 일관성이 강화(enhanced coherency)되었다고 볼 수 있습니다. 게다가 CXL 3.0 부터 호스트의 간섭 없이 Type 2 또는 Type 3 장치가 HDM에 직접 peer-to-peer 접근이 가능해져, 대규모 시스템 환경에서 안정적인 성능을 제공할 수 있게 되었습니다.
-
메모리 풀 및 메모리 공유: 이런 하드웨어 기반의 일관화를 활용해 소프트웨어의 개입 없이 CXL 메모리 풀에 연결된 메모리 장치의 한 주소 영역을 복수의 호스트가 동시(simultaneously)에 접근하고, 그 영역의 데이터가 항상 일관된 최신의 상태를 유지하는 메모리 공유(memory sharing) 개념이 추가되었습니다. 예를 들어, 호스트 1과 호스트 2가 한 메모리 장치 영역에 있는 데이터 A를 일관성을 유지하면서 각각의 로컬 메모리에 동시에 불러와 작업할 수 있다는 것입니다. 메모리 공유 기능은 GPU 서버 팜과 같이 여러 컴퓨팅 서버가 대규모 연산 작업을 수행할 때 유용하다고 볼 수 있습니다.
-
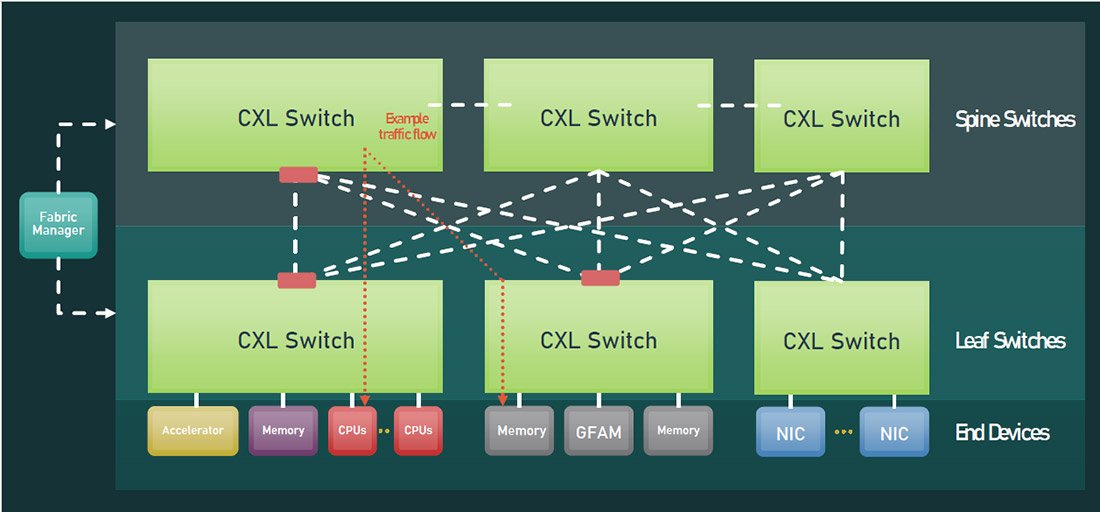
새로운 패브릭 구조: CXL 3.0의 패브릭은 이전 CXL 버전의 트리 구조와는 다른 non-tree 구조(또는 multipath 구조)를 제공하고, 포트 기반 라우팅(Port Based Routing, 이하 PBR)을 통해 최대 4,096개의 노드까지 상호 연결을 제공합니다. 이로 인해 지연 시간과 대역폭이 향상되었습니다. 여기서 말하는 노드는 모든 엔드 포인트를 의미하며, CPU 호스트나 스마트 NIC, 가속기, 메모리 장치, PCIe 장치, GFAM 장치 등이 될 수 있겠습니다. 추가로, CXL 3.1 에서는 PBR 스위치에 대한 CXL Fabric Manager API가 공개되었습니다.
-
다중 레벨 스위치 지원: CXL 2.0에서 처음 CXL 스위치를 선보이면서 스위치를 통해 호스트를 여러 장치들과 연결할 수 있게 되었고, CXL 3.0에서는 캐스캐이드 방식으로 CXL 스위치 간 계층 구성이 가능하게 되었습니다. 추가로, 호스트 당 여러 개의 Type 1과 Type 2 장치를 같이 연결시킬 수 있어, 랙 스케일 이상의 대규모 메모리 자원 풀을 구성하고 공유할 수 있겠습니다.
-
GFAM: CXL 3.0의 가장 큰 업데이트 중 하나는 바로 GFAM(Global Fabric Attached Memory)입니다. GFAM은 DRAM이나 플래시 메모리 등 휘발성 및 비휘발성 메모리 장치로 구성된 별도의 공유 메모리 풀로, CXL이 흡수한 Gen-Z 인터커넥트 의 Fabric Attached Memory를 구현한 것으로 보입니다. 구성 자체는 기존 Type 3 장치와 비슷하다고 볼 수 있겠습니다만, GFAM은 PBR을 통해 한 개 이상의 노드에서(최대 4,095개) 메모리 풀에 접근해 필요에 따라 메모리 자원을 활용할 수 있게 한다는 점이 특징입니다. 노드는 GFAM 메모리 풀에 직접 접근할 수도 있고, CXL 스위치를 통해서 접근할 수도 있습니다. 게다가 GFAM은 여러 CXL 장치들과의 연결에 MapReduce2 알고리즘을 적용할 수 있어 성능 및 효율성을 향상시킬 수 있습니다. GFAM은 이처럼 대규모 멀티 노드 구성 환경에서 복수의 호스트가 일관성이나 확장성 문제없이 공유 메모리를 활용할 수 있게 하는 것이 목적이라고 볼 수 있습니다.
-
호스트 간 로컬 메모리 공유: CXL 3.1에서는 GIM(Global Integrated Memory)라는 개념을 소개하고 있습니다. GIM은 호스트의 로컬 물리 주소 공간을 매핑한 메모리입니다. 원격의 호스트나 장치들이 RDMA나 도메인 간 메시징 목적으로 GIM에 접근할 것으로 정의하고 있으며, 캐싱이나 메모리 풀 용도가 아니기 때문에 CXL.cache나 CXL.mem으로는 사용이 제한됩니다.
-
가상화 기반 TEE 보안 프로토콜 지원: CXL 3.1부터는 TSP (Trusted Execution Environments Security Protocol)를 통해 기존 호스팅 환경과는 격리된 보안 환경에서 직접 연결된 CXL Type 3 메모리 풀 간의 기밀 컴퓨팅 워크로드를 호스팅할 수 있습니다.
-
메모리 확장 장치 개선: CXL 3.1에서는 캐시 블록의 상태(변경, 공유 등)에 대한 2-bit 메타데이터에 32-bit를 추가했습니다. 이 34-bit 메타데이터는 접근 권한, 데이터 태깅, 메모리 티어링 등이 주 용도이고, DDR6의 메타데이터 확장 기능과도 연계 가능합니다. 게다가 각종 메모리 오류에 대한 정보를 추가해 RAS(Reliability, Availability, and Serviceability)를 개선했습니다.
CXL과 스토리지의 관계
CXL은 프로세서가 활용할 수 있는 메모리 가용량을 높여 컴퓨팅 성능을 가속하고, 메모리 확장 시 발생하는 비용을 최소화하는 것이 주 목적입니다. 다만, 이처럼 CXL을 통해 컴퓨팅 성능과 비용 효율은 확보할 수 있지만, 데이터 이동으로 인한 대역폭 부하가 높아질 것이기 때문에 스토리지 대역폭에 대한 요구사항은 높아질 수밖에 없습니다. 게다가 대규모 메모리 자원을 요구하는 애플리케이션의 경우, CXL 메모리 풀을 통해 보다 더 많은 메모리 자원을 활용할 수 있고, 메모리 자원이 분산되어 있어 입출력에 대한 부하는 낮지만, 이후 작업이 끝나고 메모리가 재할당되는 과정에서 스토리지에 가해지는 부하는 급격하게 높아질 수 있습니다.
하지만 CXL은 스토리지 성능 향상에도 도움을 줄 것으로 보입니다. CXL은 호스트의 간섭 없이 peer-to-peer 읽기 및 쓰기로 데이터를 메모리에서 이동시킬 수 있어 RDMA 방식(호스트가 중간에 낌)에 비해 빠른 접근이 가능합니다. 또한, 태스크 스위칭이 일어날 때마다 호스트가 IO 스트림을 개시하거나 멈출 필요가 없기 때문에 보다 많은 전송량을 제공할 수 있고, 호스트 부하도 줄일 수 있어 입출력 성능이 향상될 수 있습니다. 무엇보다 기존 시스템 구성에 비해 메모리 자원이 커지기 때문에 캐시로 활용하는 경우, 읽기 캐시나 쓰기 캐시로 활용하는 메모리 공간도 커질 수 있어, 스토리지에 대한 부하도 그만큼 줄어들 수 있습니다.
마치며
CXL은 현재 인터커넥트 중에서도 독보적인 관심을 받는다고 할 수 있을 정도로, 차세대 메모리 인터커넥트로써의 위치를 공고히 하고 있습니다. 다만, 이제 막 CXL 1.1이나 2.0을 적용한 디바이스가 출시된 상황이기 때문에 조금 더 지켜볼 필요가 있겠습니다.
참고
- https://www.computeexpresslink.org/spec-landing
- https://www.computeexpresslink.org/_files/ugd/0c1418_a8713008916044ae9604405d10a7773b.pdf
- https://www.computeexpresslink.org/_files/ugd/0c1418_6ede12bda4d34ffeb879c3700dde38f9.pdf
- https://community.cadence.com/cadence_blogs_8/b/fv/posts/navigating-cache-coherence-the-back-invalidate-feature-in-cxl-3-0
- https://arxiv.org/ftp/arxiv/papers/2306/2306.11227.pdf
- https://www.anandtech.com/show/17520/compute-express-link-cxl-30-announced-doubled-speeds-and-flexible-fabrics
- https://www.synopsys.com/designware-ip/technical-bulletin/cxl2-3-storage-memory-applications.html
- https://www.openfabrics.org/wp-content/uploads/2023-workshop/2023-workshop-presentations/day-2/202_MWagh.pdf
- https://www.servethehome.com/cxl-3-1-specification-aims-for-big-topologies/
- https://www.techtarget.com/searchstorage/tip/How-the-CXL-interconnect-will-affect-enterprise-storage
- https://www.techtarget.com/searchstorage/feature/How-CXL-30-technology-will-affect-enterprise-storage
각주
-
HDM (Host-managed Device-attached Memory): 시스템 주소 공간에 매핑되어 호스트 측에서 일반적인 write-back 방식으로 접근 가능한 메모리를 말함. 주소 공간에 매핑이 안되어 있으나, 호스트에서 접근 가능한 메모리는 PDM(Private-managed Device-attached Memory)이라고 하며, CXL 장치의 메모리는 HDM과 PDM으로 구분됨. ↩
-
MapReduce: MapReduce를 도입한 시스템은 분산 서버의 다양한 태스크를 병렬로 수행하고, 다양한 영역의 시스템 간의 모든 통신과 데이터 전송을 관리하고, 장애 내구성과 가용성을 오케스트레이트할 수 있음. 주로 컴퓨터 노드 클러스터에서 사용하는 대규모 데이터셋의 병렬 처리에 적합하며, 데이터가 저장된 곳에서 처리(locality of data)할 수 있게 해 통신 부하를 최소화하는 것이 목적임. ↩