스토리지 기초 지식 6편: 데이터 보호 - RAID와 소거 코드
by 박 주형 (jhpark@gluesys.com)
스토리지 시스템에 있어서 데이터 보호(data protection)는 기업 정보 자산을 보호하는 데 의의를 두고 있습니다. 그 자산은 운용 중인 핵심 어플리케이션이나 서비스에 등록된 고객 정보일 수도 있기 때문에, IT 관리자들은 스토리지 시스템을 구축하기에 앞서 자사의 인프라와 사용 목적을 파악하고 그에 따른 데이터 보호 방법을 강구해야 합니다. 스토리지의 데이터 손실을 복구할 수 있는 가장 확실한 방법은 데이터의 복제본을 만들어두고 문제 발생 시 복사본으로 복구하는 것입니다. 스냅샷(snapshot)처럼 시스템 데이터 및 설정을 복제해서 로컬 또는 원격의 다른 스토리지로 백업하는 방법이 있는가 하면, 시스템 범위 내에서 데이터 보호가 이루어 지는 방법이 있습니다. 이번에 소개할 RAID와 이레이저 코딩이 바로 그것입니다.
RAID에 대해서
스토리지를 접해보신 분이라면 한 번쯤 RAID에 대해 들어 보셨을 것입니다. RAID는 스토리지 가상화 기술의 일종으로, 한 디스크가 차면 다음 디스크에 저장하는 기본적인 JBOD 방식에서 성능과 데이터 무결성을 확보하기 위해 만들어졌습니다. RAID(Redundant Array of Independent Disks)라는 용어는 말 그대로 여러 개의 데이터 조각으로 배열된 각각의 디스크를 말합니다. 여기서 배열이란 한 뭉텅이인 데이터를 쪼개서 각 디스크에 저장하는 것을 의미하며, 이 배열 방식은 크게 스트라이핑(striping)과 미러링(mirroring)으로 나뉩니다.
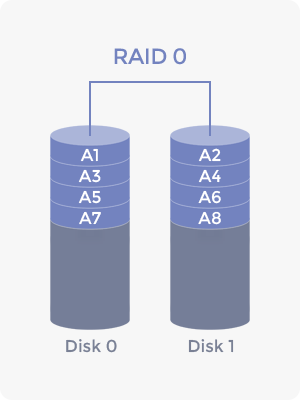
스트라이핑은 한마디로 병렬 처리라고 보시면 됩니다. A라는 데이터를 하나의 디스크에서 불러오는 것보다 각 디스크에 저장된 A의 조각들을 동시에 불러와서 모으는 편이 빠르고 디스크별 부하도 줄일 수 있는 장점이 있습니다. 다만, 디스크 하나가 망가지면 해당 디스크의 데이터 조각은 없어지기 때문에 데이터의 무결성에 문제가 발생합니다.
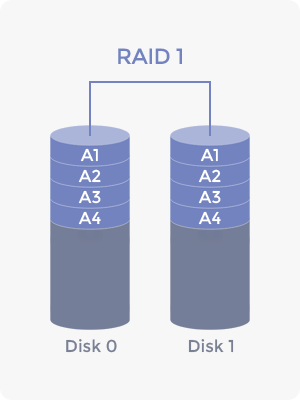
미러링은 거울에 비추듯이 같은 데이터를 복수의 디스크로 동시에 저장하는 것을 말합니다. 디스크 하나가 망가져도 다른 디스크에 같은 데이터가 존재하기 때문에 해당 데이터를 보존할 수 있지만, 그 데이터만큼의 추가 공간을 차지하기 때문에 공간 효율 측면에서는 좋지 못합니다.
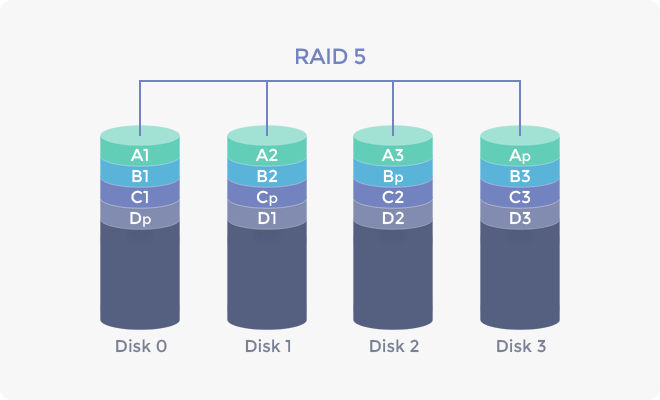
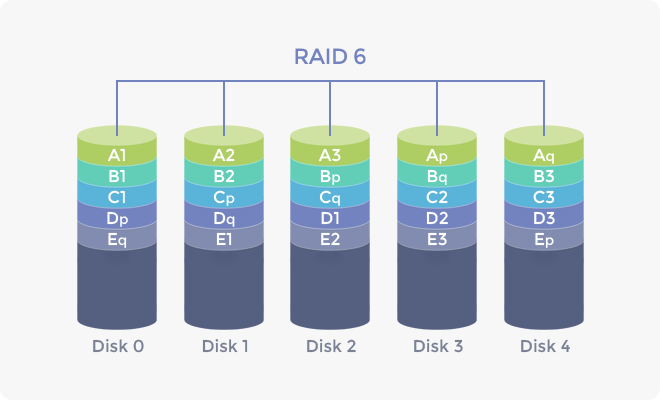
마지막으로 RAID는 패리티(parity)라는 데이터 복구 수단을 두고 있습니다. 패리티는 원본 데이터를 특정 알고리즘을 활용해 생성할 수 있는 추가 데이터를 의미합니다. 아래 RAID 5 구성의 경우 데이터별 패리티를 1개씩 생성하며, XOR 비트 연산이라는 계산법을 활용합니다. 아래 그림과 같이 데이터 A, B, C, D가 디스크 4개에 저장되면 3개씩 나누어진 데이터를 XOR 연산으로 계산해 패리티를 생성하고 스트라이핑으로 저장합니다. 만일 2번 디스크가 망가졌을 경우, 1번, 3번, 4번 디스크에 저장된 데이터 조각과 패리티를 다시 XOR 연산으로 계산해 2번 디스크의 데이터 조각을 복구할 수 있습니다. 다만, 아래의 RAID 5 구성처럼 4개의 디스크 중에서 2개가 망가졌을 경우 1개 패리티만으로는 전체 데이터의 복구가 불가능합니다. 이를 보완하기 위한 것이 RAID 6입니다. RAID 6는 스트라이핑으로 저장하는 점에서 RAID 5와 같지만, 패리티가 1개가 아닌 2개씩 구성됩니다. 또한 XOR 연산이 아니라 Reed-Solomon 부호로 패리티를 생성합니다. 다만, 패리티를 늘리게 되면 패리티 생성을 위한 추가 공간이 필요할 뿐 만 아니라 패리티 생성 및 복구로 인한 CPU 부하의 증가를 야기할 수 있습니다.
이처럼 스트라이핑, 미러링, 패리티에 대해 소개해 보았습니다만, 이를 어떻게 구성하는지에 따라 RAID 수준이 달라지고 기업들은 인프라의 특성에 맞는 RAID 수준을 구축해야 합니다. 이 모든 작업은 별도의 하드웨어 컨트롤러나 서버의 OS 내에서 진행할 수 있으며, 이를 각각 하드웨어 RAID와 소프트웨어 RAID 라고 합니다.
하드웨어 RAID는 말 그대로 별도의 하드웨어인 RAID 컨트롤러 카드를 통해 RAID를 구현합니다. 하드웨어 단에서 처리되는 만큼 시스템에 부담 없이 읽기/쓰기나 패리티 계산 등의 속도가 빠르지만, 별도의 하드웨어 애드온인 RAID 컨트롤러 카드의 가격이 비싸다는 단점이 있습니다. 반면, 소프트웨어 RAID는 단순히 메인보드에서 직접 RAID 기능을 구현합니다. RAID를 적용할 디스크만 있으면 별도의 하드웨어가 필요 없어 비용은 아낄 수 있지만, 다른 작업들과 CPU 리소스를 공유하기 때문에 전반적인 작업 속도가 느려질 수 있습니다. 이 때문에 소프트웨어 RAID에서는 오버헤드가 가장 낮은 RAID 0이나 RAID 1을 사용하는 경우가 많습니다.
RAID는 기본적으로 한 개나 두 개 정도의 디스크 오류에 대처할 수 있을 정도로만 쓰여 왔고, 디스크 용량도 크지 않아 복구 작업이 수 분에서 수 시간만 걸릴 정도였습니다. 하지만 단일 저장장치의 용량이 수TB로 커지게 되면서 RAID의 실용성에 의문이 제기되고 있습니다. 거대한 용량을 다루게 되면서 디스크 복구 작업이 며칠이나 걸리게 되고 그동안 한두 개의 디스크 오류에 대처 가능한 정도로는 부족하기 때문입니다. 이 때문에 최근에 이를 보완할 수 있는 기술로서 이레이저 코딩이 대두되고 있습니다.
이레이저 코딩이란
이레이저 코딩(erasure coding)은 RAID와 마찬가지로 데이터 손실 시 미리 준비된 별도의 데이터(패리티)로 복구하는 기술입니다. 기본적인 개념은 같아서 동일시하는 경우도 있지만, 별도의 데이터를 계산하는 방법에서 차이가 있습니다.
우선 이레이저 코딩에서도 RAID처럼 원본 데이터를 여러 데이터 조각으로 나눕니다. 이 데이터 조각을 가지고 RAID 6처럼 Reed-Solomon 부호를 사용한 변환 작업을 거쳐서 추가적인 데이터 패리티들을 생성합니다. 여기서 RAID와의 차이점은 데이터 보호 수준을 유연하게 설정할 수 있다는 점입니다. 예를 들어 10조각짜리의 블록을 인코딩해서 추가로 6조각의 패리티를 생성하는 경우, 이렇게 변환된 총 16조각의 데이터는 16군데의 노드나 디스크에 분산 저장할 수 있습니다. 중요한 것은, 이 16조각의 데이터에서 원본 데이터로 복구하기 위해 필요한 조각은 10조각이라는 것입니다. 한마디로 16개의 디스크에 분산 저장되었다면 디스크 오류가 여섯 군데에서 발생해도 원본 데이터를 복구할 수 있다는 의미입니다. 이는 RAID에 비해 더 많은 디스크 오류에 대처할 수 있다는 의미이며, 원본 데이터를 생성하기 위해 모든 데이터 조각을 읽을 필요도 없습니다. 또한 대처 가능 오류 수에 대비해 추가공간을 적게 차지합니다.
이처럼 이레이저 코딩이 RAID의 대체 기술이 될 것처럼 보이지만, 단점도 확실히 존재합니다. 우선 소프트웨어 RAID처럼 모든 작업이 소프트웨어로 처리되고 모든 데이터를 인코딩하는 만큼 패리티 계산에 CPU 오버헤드와 지연시간이 발생합니다. 이 때문에 블록 스토리지와 같이 작은 블록 입출력이 발생하는 스토리지 시스템은 블록별 계산이 많아지기 때문에 전반적인 스토리지 성능에 영향을 줄 수 있습니다.
RAID와 이레이저 코딩의 용도
이처럼 RAID와 이레이저 코딩의 개념과 장단점에 대해 다루어 보았습니다만, 실제로 어떤 인프라 구성에 적합한지에 대해 다루어 보고자 합니다.
-
HCI (Hyperconverged Infrastructure): 기본적으로 RAID는 단일 스토리지 어레이에 적합한 반면, 이레이저 코딩은 여러 노드에 분산 저장할 수 있어 스케일아웃 시스템에 적합하다고 볼 수 있습니다. 우선 RAID는 도입할 수 있는 구성이 정해져 있고, 허용할 수 있는 디스크 오류 숫자가 매우 적다 보니 다수의 노드로 구성된 하이퍼컨버지드 시스템에 적합하지 않습니다. 이레이저 코딩의 경우, 전 노드에 데이터를 분산시켜서 관리할 수 있어 적합하다고 볼 수 있습니다. 다만 쓰기가 빈번하게 일어나거나 고성능이 요구되는 경우 이레이저 코딩의 사용은 제한적일 수밖에 없습니다.
-
플래시 스토리지: 플래시 스토리지는 매우 빠른 입출력을 지원하지만, 단일 저장장치의 용량은 하드디스크에 비해 크지 않은 특성을 가지고 있습니다. 이레이저 코딩은 일반적으로 복수의 저장매체나 노드를 대상으로 데이터 보호를 제공하도록 디자인되었기 때문에 여기서 발생하는 지연시간은 플래시 스토리지의 장점을 희석시킵니다. 그러나 앞으로 SSD의 용량이 하드디스크만큼 커지게 된다면 RAID의 제한적인 확장성 문제를 보완하기 위해 활용될 수도 있겠습니다.
-
오브젝트 스토리지: 오브젝트 스토리지는 백업이나 아카이브 등 대용량 스토리지로 주목받고 있습니다. 무엇보다 이전과는 달리 사용하는 용량의 규모가 늘어난 만큼, 데이터 재구성 시간이 오래 걸리는 RAID의 효율도 점점 낮아지고 있습니다. 또한 오브젝트 스토리지의 특성상 거대한 비정형 데이터를 노드에 걸쳐 분산 저장할 수 있고 심플한 확장성 때문에 이레이저 코딩과 활용이 용이합니다.
마치며
RAID는 30년 가량의 역사를 가진 매우 보편화된 기술로 지금까지도 그 성능과 가용성 보장 기술의 가치는 인정받고 있습니다. 그러나 단일 저장매체의 크기가 날로 증가하고 있고 이에 따른 확장성 요구가 증가하면서 스토리지에 사용되는 지분을 점차 잃어가고 있습니다. 다만 블록 스토리지가 앞으로도 계속 활용되는 이상, 블록 스토리지에 최적화된 RAID가 없어질 일은 없을 것으로 보입니다.
참고
RAID vs 이레이저 코딩:
- https://searchvmware.techtarget.com/answer/What-is-the-difference-between-erasure-coding-RAID-5-and-RAID-6?_ga=2.58430434.999995828.1595203797-1783747986.1586150826
- https://www.computerweekly.com/feature/SSD-Raid-101-The-essentials-of-flash-storage-and-Raid?_ga=2.146756852.1150977372.1594864846-1783747986.1586150826
- https://searchstorage.techtarget.com/tip/Why-object-storage-is-becoming-an-alternative-to-RAID?_ga=2.146756852.1150977372.1594864846-1783747986.1586150826
- https://www.snia.org/sites/default/files/SDC15_presentations/datacenter_infra/Shenoy_The_Pros_and_Cons_of_Erasure_v3-rev.pdf