스토리지 이중화 1편: 고가용성과 이중화
by 김 태훈 (thkim@gluesys.com)
기업은 사내 전산 시스템이나 IT 서비스를 안정적으로 운영하기 위해 많은 시간과 비용을 투자하고 있습니다. 특히 서비스가 중단되는 시간을 뜻하는 다운타임(Downtime) 을 최소화 하기위해 모든 시스템을 이중화로 구성하고 장비의 상태를 지속적으로 확인하면서 정상적인 서비스를 유지하기위해 노력합니다. 이렇게 서비스를 안정적인 상태로 오래 기간 운영하는 성질을 고가용성(HA: High Availability) 이라고 표현합니다. 고가용성은 단어 그대로 높은 가용성을 보장한다 라는 뜻을 나타내며, 99%, 99.9%와 같은 퍼센티지로 서비스 품질 수준을 표현합니다1.
이중화에 대해서
높은 가용성을 보장하기 위해서는 어떤 방법이 있을까요? 이는 앞서 언급한 이중화에 핵심이 있습니다. 이중화는 시스템에 장애가 발생할 것을 대비해서 동일한 기능을 수행하는 예비 시스템을 동시에 운용하는 행위를 뜻합니다. 따라서 이중화 환경은 단일 시스템 환경보다 더 많은 구축 비용이 발생하며, 관리할 장비가 많아진 만큼 유지보수 비용 또한 높아집니다. 하지만 높아진 비용만큼 서비스가 중단될 확률을 낮출 수 있으며, 예상치 못한 장애가 발생하더라도 빠른 시간안에 복구가 가능해집니다.
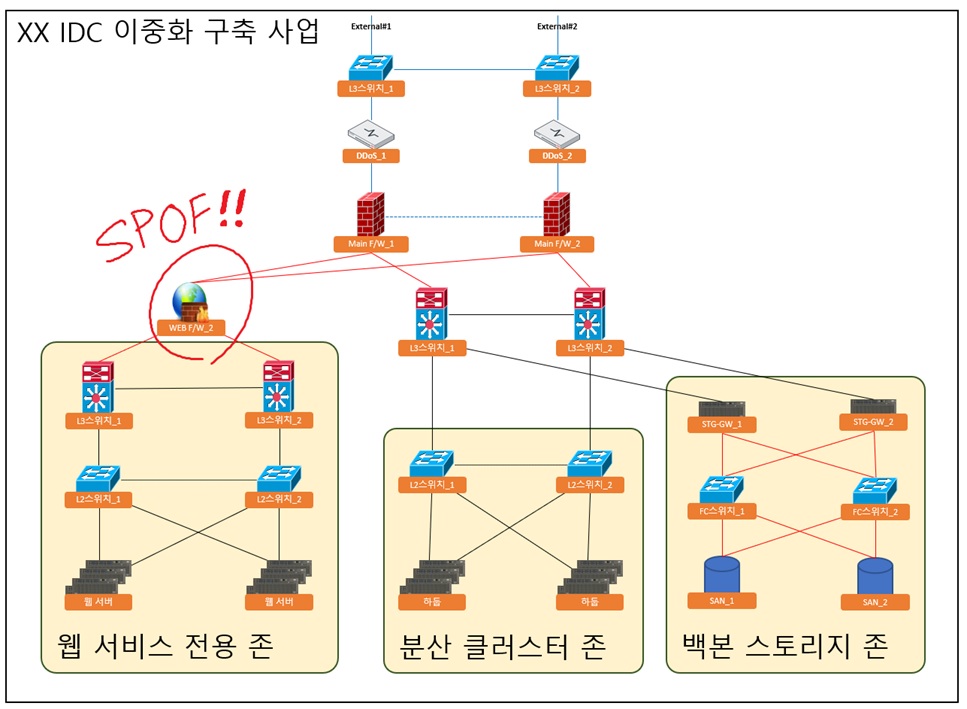
고가용성이 보장되는 서비스 환경을 구축하기 위해 이중화 구성이 필요한 부분과 그렇지 않은 부분에 대해서 판단할 수 있어야 합니다. 또한 물리적인 시스템 외에도 소프트웨어의 핵심 기능들도 이중화 대상으로 인식하고 필요할 경우 모니터링을 수행하여 관리해야 합니다. 만약 장애가 발생할 수 있는 지점을 정확하게 확인하지 못한다면 단일 장애점(SPOF : Single Point of Failure)2 이 되어 서비스 장애로 이어질 수 있는 잠재적 요인이 될 수 있습니다. 반대로 불필요한 요소까지 이중화를 한다면 서비스에 영향이 없는 부분의 결함도 장애로 인식3하여 failover4 발생 시 원인 추적에 방해를 주거나 모니터링에 어려움을 겪는 등 시스템 운영에 혼란을 줄 수 있습니다.
따라서 이중화 환경을 구성할 때에는 서비스(소프트웨어)와 서버, 네트워크, 스토리지 등 각 분야에 전문성 있는 팀을 구성하여, 운영하고자 하는 환경과 서비스 목적에 알맞은 이중화 시스템을 구축할 수 있어야 합니다.
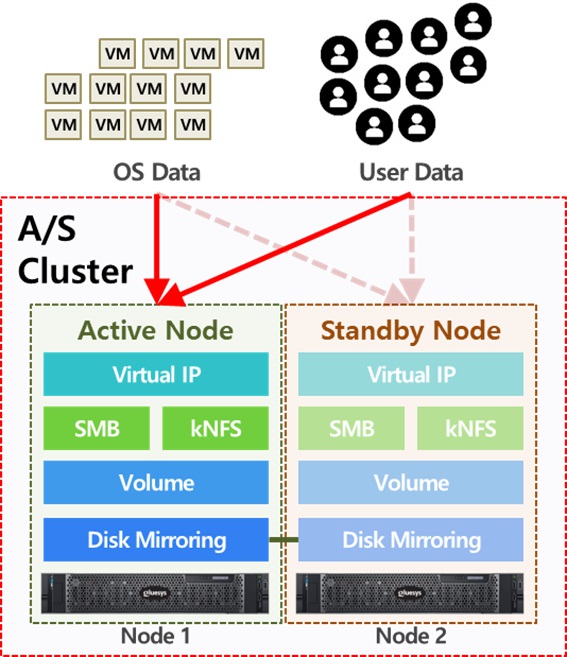
이중화는 크게 두 가지 방법으로 구성할 수 있습니다5. 첫번째는 Active/Standby 구성으로 HA 클러스터링 된 다중 서버 환경에서 한 대의 서버는 활성 상태(이하 Active)로 동작하고 나머지 서버들은 대기 상태(이하 Standby)로 동작합니다. 클러스터로 연결된 모든 서버는 heartbeat6로 연결되어 서버와 모니터링중인 서비스들의 상태를 주고받습니다. 이때 Active 서버에서 장애가 발생한다면 HA 클러스터는 Standby 서버 중에서 점수(Score)가 가장 높은 서버에게 서비스를 이관합니다.
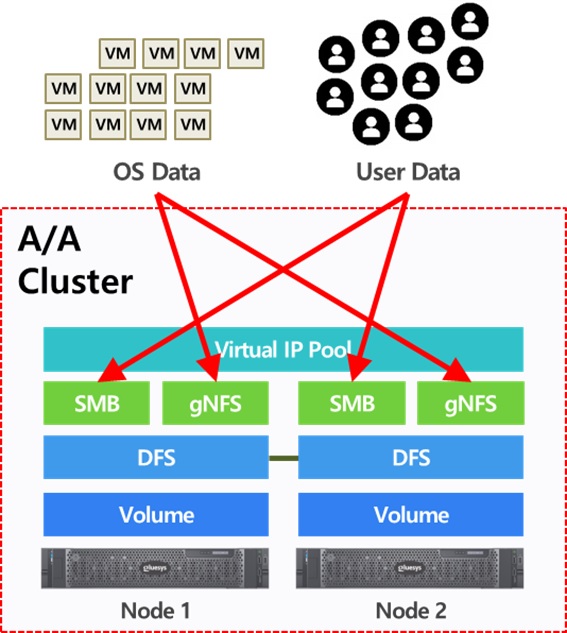
두 번째는 Active/Active 구성입니다. Active/Active는 HA 클러스터로 연결된 모든 서버가 Active 서버로 동작하는 환경입니다. 흔히 부하 분산 모드(Load-Balancing) 로 불리기도 합니다. Active/Active 구성의 장점은 Active/Standby 비용으로 더 높은 처리량(Throughput)을 가질 수 있지만, 장애 발생 시 제외된 Active 서버의 대수만큼 처리량이 낮아지기 때문에 서비스 장애로 확대될 수 있습니다. 따라서 장애 상황에서도 안정적인 상태를 유지하기 위해서는 Active/Standby 구성보다 더 높은 처리량을 갖는 서버나 더 많은 대수로 구성하는 것이 안전합니다.
장애 상황 및 후속 조치
이중화 구성에서 장애 상황은 크게 세 가지로 구분할 수 있습니다. 첫번째는 하드웨어 장애 상황으로 전원 공급 장치에 이상이 발생하거나 컴퓨팅 구동에 핵심인 CPU와 메모리, 디스크 장애 등을 포함합니다. 서버 급 컴퓨터의 경우 전원 이중화, 듀얼 CPU 및 메모리, RAID 구성을 통해 방지할 수 있으나, 일반적인 PC 사양의 컴퓨터는 하드웨어 장애 상황을 대비하기 어렵습니다. 만약 하드웨어 장애가 발생할 경우, 운영체제 레벨에서 처리가 되겠지만, 시스템이 멈춰버린다면(흔히 hang이라고 표현합니다) HA 클러스터 레벨에서 heartbeat를 확인하여 시스템 정지를 확인하고 이후 failover 절차를 수행합니다.
두번째는 서비스 장애 상황입니다. 서비스 장애는 서버에서 동작하는 프로그램(어플리케이션)과 서비스 데몬(Daemon)에 장애가 발생한 것을 뜻합니다. 흔히 서비스는 데이터베이스, 아파치 웹, FTP와 NFS 같은 파일 공유 프로토콜 등을 포함합니다. 만약 서비스 장애가 발생하면 HA 클러스터는 장애를 인지하고 필요 시 복구 절차를 수행하며, 복구에 실패할 경우 failover를 수행하여 Active 서버를 이전합니다.

마지막으로 네트워크 장애 상황입니다. 네트워크 장애는 서버와 서버, 또는 장치를 연결하는 서버의 네트워크 레벨에서 발생하는 장애를 뜻합니다. 예를 들어 이더넷 네트워크인 네트워크 인터페이스 카드(NIC : Network Interface Card)는 IP 주소를 통해 통신을 수행하며, NIC에서 발생한 장애나 유효하지 않은 IP 주소가 입력되어 통신이 되지 않은 상황들을 예로 들 수 있습니다. 또한 스토리지 네트워킹 장치인 파이버 채널(FC : Fibre Channel)7과 고성능 컴퓨팅 환경에서 사용되는 인피니밴드(IB : InfiniBand)8도 네트워크 장애 범위에 포함됩니다. 네트워크는 본딩(Bonding)9과 티밍(Teaming) 등을 이용하여 다수의 인터페이스를 하나로 구성하여 인터페이스 장애 상황에서도 downtime 없이 서비스를 지속할 수 있습니다.
IT 관리자는 모니터링을 통해 failover가 발생한 것을 확인했다면, 장애가 발생한 서버를 신속하게 확인해야합니다. 물론 Standby 서버가 다수일 경우 추가 장애가 발생하더라도 failover 할 수 있는 여유 노드가 존재하기 때문에 서비스 장애(Downtime이 발생하는 상황)로 확대될 가능성은 낮습니다. 하지만 잘못된 지점을 모니터링하거나 확인하지 못한 지점에서 장애가 발생한 경우 등, 예상하지 못한 상황이 발생할 때, 클러스터링 된 서버들은 모두 동일한 환경이기 때문에 동일한 이유로 failover가 발생할 수 있습니다. 따라서 위와 같은 원인일 경우에는 모니터링 설정 변경 또는 새로운 장애 지점에 대한 모니터링 수행 등 추가 조치를 신속하게 수행해야 합니다.
스토리지 이중화
스토리지는 데이터가 최종적으로 저장되는 장치이며, 스토리지 중에서도 네트워크 기반의 공유 환경을 제공하는 NAS(Network Attached Storage)는 데이터 저장뿐만 아니라 공유 서비스, 사용자 인증 서비스, 네트워크 환경까지 고려해야 합니다. 따라서 NAS 이중화는 파일 저장과 공유 기능에 영향을 줄 수 있는 장애 지점들을 모두 파악하고 관련된 자원들을 모니터링해야 합니다. 또한 SAN(Storage Area Network)과 DAS(Direct Attached Storage)와 같이 블록 스토리지가 추가로 연결된다면, 모니터링이 필요한 지점은 증가할 것입니다.
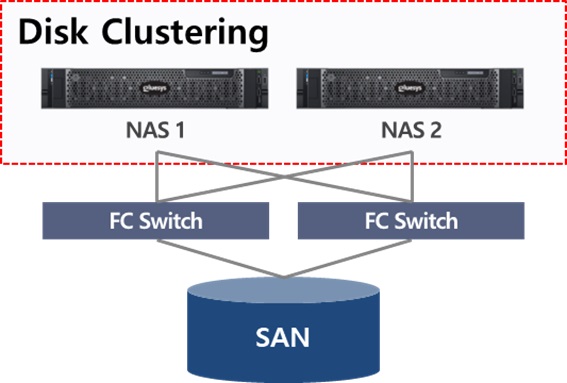
NAS 이중화 구성에서 디스크를 클러스터링 하는 방법은 크게 두 가지로 구분할 수 있습니다. 첫번째는 디스크 공유 방식으로, 별도로 구성된 SAN과 DAS와 같은 블록 스토리지의 볼륨을 NAS를 통해 공유하는 것입니다. 이 경우, NAS와 블록 스토리지는 (일반적으로)파이버 채널 네트워크로 연결됩니다. 디스크 공유 방식은 NAS와 데이터 저장 공간이 물리적으로 분리되기 때문에 NAS를 추가로 확장하거나 교체를 하더라도 원본 데이터는 블록 스토리지에 저장되어 있는 것이 특징입니다.
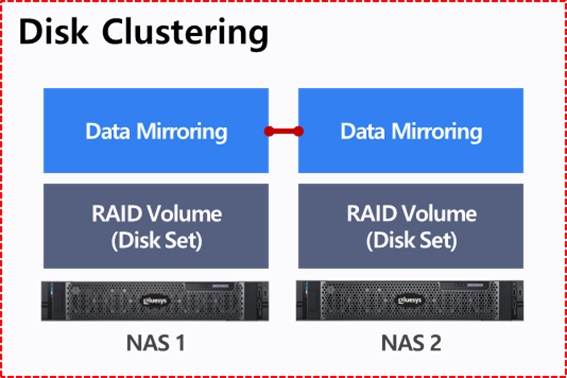
두번째는 데이터 동기화 방식입니다. 데이터 동기화 방식은 디스크 공유 방식과 다르게 별도의 스토리지가 존재하지 않으며, NAS에 데이터가 저장될 디스크(Disk Set)가 설치되는 일체형 환경입니다. 각각의 NAS에는 물리적으로 분리된 디스크가 할당되기 때문에 데이터 또한 분리되어 있습니다. 따라서 모든 NAS의 데이터를 동기화하기 위해서는 별도의 데이터 복제 기술이 필요합니다. 데이터 복제 기술에 따라서 다르지만 보편적인 방법으로 디스크 클러스터를 구성할 경우 10G 이더넷 또는 인피니밴드를 사용하기도 합니다.
위처럼 데이터가 저장되는 디스크의 위치에 따라서 디스크 클러스터링 방법을 선택해야 합니다. NAS는 모든 환경에서 Active/Active와 Active/Standby를 위한 서비스 이중화 구성이 가능합니다. Active/Active와 Active/Standby에 대한 자세한 구성 방법은 다음 포스트에서 실 구축 사례와 같이 설명하도록 하겠습니다.
마치며
이번 포스트에서는 이중화의 기본 개념에 대해서 설명했으며, 더 나아가 IT 관리자 시점에서 고가용성을 높이기 위한 방법은 어떤 것이 있는지 알아보았습니다. 그리고 스토리지 분야에서 NAS 이중화 구성에 필요한 배경 지식과 디스크 구성 환경에 따른 디스크 클러스터링 방법을 살펴보았습니다.
다음 포스트에서는 이중화 구성에 사용하는 오픈소스 프로젝트를 소개하고, NAS 이중화를 위한 시스템 디자인 방법과 다년간 스토리지 이중화 구축 및 유지보수를 통해 얻은 경험을 공유 하겠습니다. 감사합니다.
참고
- http://egloos.zum.com/gunsystems/v/6782436
- https://www.sharedit.co.kr/posts/53
- https://zdnet.co.kr/view/?no=20101220174657
각주
-
https://en.wikipedia.org/wiki/High_availability ↩
-
https://en.wikipedia.org/wiki/Single_point_of_failure ↩
-
https://en.wikipedia.org/wiki/Fault_tolerance#Terminology ↩
-
https://en.wikipedia.org/wiki/Failover ↩
-
https://en.wikipedia.org/wiki/High-availability_cluster#Node_configurations ↩
-
https://en.wikipedia.org/wiki/Heartbeat_(computing) ↩
-
https://en.wikipedia.org/wiki/Fibre_Channel ↩
-
https://en.wikipedia.org/wiki/InfiniBand ↩
-
https://en.wikipedia.org/wiki/Link_aggregation ↩