스토리지 기초 지식 7편: 데이터 보호 - 스냅샷
by 박주형 (jhpark@gluesys.com)
윈도우에는 시스템 복원(맥에서는 타임머신)이라는 기능이 있습니다. 윈도우 업데이트 문제로 시스템 오류가 발생하거나 실수로 중요한 자료를 지워버렸을 때 이 시스템 복원 기능을 사용하면 마치 과거로 시간 여행하듯이 컴퓨터를 과거의 복원 시점으로 되돌릴 수 있습니다. 새로 생성한 데이터는 존재하지 않게 되지만, 수정되거나 삭제된 데이터는 과거의 상태로 돌아오게 됩니다. 이번에 소개해 드릴 스냅샷(snapshot) 기능은 이와 비슷하지만 조금 더 다양한 정책을 통해 스토리지에 데이터 보호 효과를 제공합니다.
스냅샷이란
스냅샷은 위에서 설명해 드린 시스템 복원 기능과 같이 스토리지에 저장된 데이터를 과거 시점으로 되돌릴 수 있습니다. 특정 시점에서 스냅샷을 생성하게 되면 백업처럼 원본 데이터(original data)를 별도로 준비된 스냅샷 공간(snapshot pool)에 복제해 놓고, 나중에 원본 데이터에 문제가 발생하게 되면 복원 작업을 진행합니다. 이처럼 특정 시점의 데이터를 복사해 놓는 방식을 point-in-time copy라고 합니다. 단어 ‘스냅샷’의 의미인 ‘순간적으로 찍은 사진’처럼, 과거 시점의 시스템 상태를 마치 사진을 찍어서 그 순간을 남긴다는 개념을 떠올리시면 됩니다.
이번 시간에 소개해 드릴 스냅샷 종류는 다음과 같습니다.
Split-mirror 스냅샷
Split-mirror(또는 클론) 스냅샷은 스냅샷 설정 시 원본 데이터를 통째로 복제하는 방식으로, 가장 단순한 형태의 스냅샷이라고 볼 수 있습니다. 데이터가 통째로 복제되기 때문에 저장 방식과 구조가 단순하고, 무엇보다 원본에 문제가 생겼을 경우 다시 통째로 복원할 수 있다는 장점이 있습니다. 다만 원본 데이터와 같은 양의 스토리지 공간이 요구되기 때문에 다른 스냅샷 방식과 비교해 공간 효율이 떨어지고, 데이터의 양이 커질수록 스냅샷이 생성되는 속도가 느려지기 때문에 가용량과 성능에 부담을 줄 수 있습니다. 이 때문에 스냅샷 공간을 둘로 나누어 절반만 먼저 복제해서 속도와 공간을 확보하는 식으로 활용할 수도 있습니다.
Copy-on-write 스냅샷
Copy-on-write(이하 COW) 방식은 가장 널리 쓰이는 스냅샷 방식 중 하나입니다. ‘Copy-on-write’라는 의미 그대로 쓰기 작업(write)이 있을 시 데이터를 복제(copy)하기 때문에 실질적인 데이터 처리는 데이터가 변경되는 시점에서 이루어집니다.
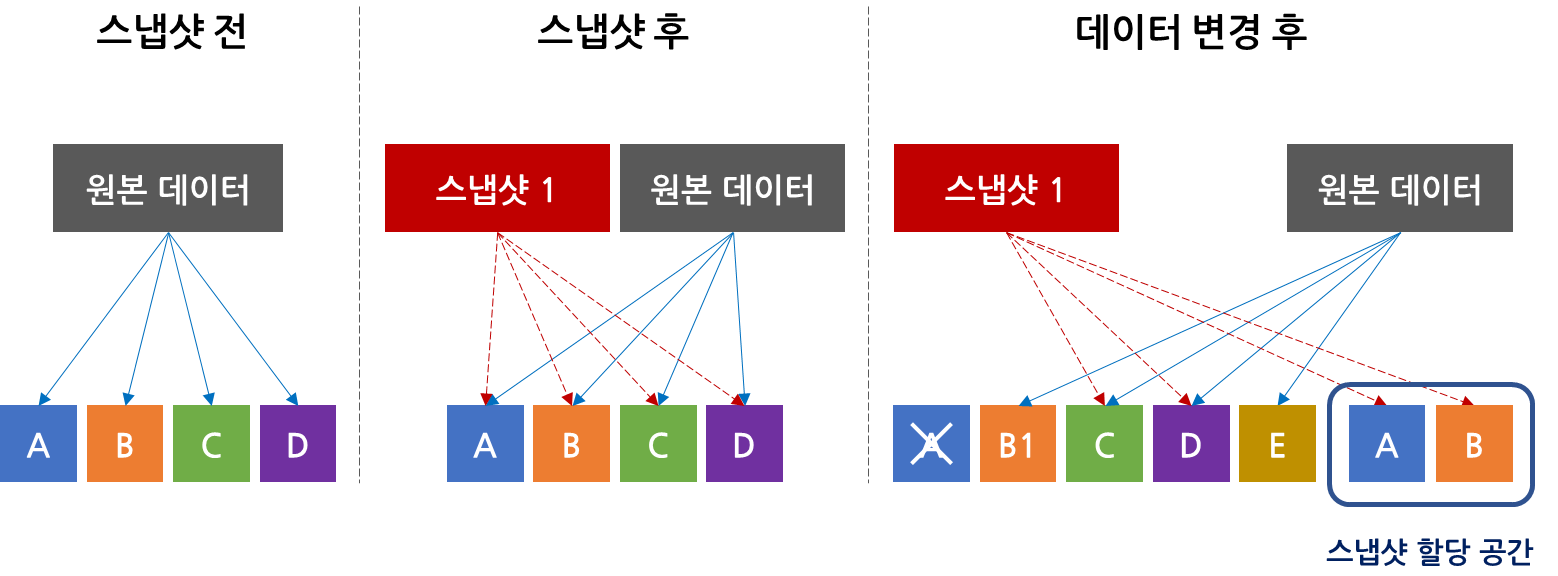
스냅샷 생성 시, 미리 확보해 놓은 스냅샷 공간에 바로 복제하지 않고 메타데이터만 만들어 놓기 때문에 거의 바로 생성됩니다. 위의 그림처럼 스냅샷 1을 생성하면 스냅샷이 원본 데이터 A, B, C, D의 위치를 가리키고 있는데, 이를 포인터(pointer)라고 합니다. 이 포인터를 통해 스토리지의 파일시스템이나 컨트롤러가 데이터를 추적할 수 있습니다. 여기서 데이터가 수정되는 경우, COW 스냅샷에서는 원본 데이터를 미리 할당해 놓은 스냅샷 공간에 복제해 놓고 새로 수정된 데이터를 기존 위치에 덮어씁니다.
다시 위 그림을 예시로, 데이터 A를 삭제하고, 데이터 B를 수정하고, E라는 데이터를 새로 생성하는 경우를 가정해 보겠습니다. 데이터의 변경에 대한 요청이 들어오면 변경되는 데이터 A와 B에 대한 위치를 포인터로 추적해 데이터 읽기를 진행합니다. 읽어 들인 원본 데이터 A와 B는 스냅샷 공간으로 쓰기를 진행하고 포인터를 재설정합니다. 마지막으로 데이터 A와 B를 수정하고 새로운 데이터 E의 쓰기를 진행합니다. 이후 스냅샷 1에 요청이 들어오면 변경되지 않은 데이터 C와 D, 그리고 스냅샷 공간의 데이터 A와 B를 가리키는 포인터를 통해 불러올 수 있습니다.
COW 스냅샷은 즉각적으로 스냅샷을 생성할 수 있고, 변경되지 않은 데이터는 포인터로 지정해 놓기만 하면 되기 때문에 split-mirror 방식보다 데이터 이동이 적습니다. 하지만, 변경될 데이터를 스토리지 OS가 한번 읽어야 하고, 스냅샷 공간에 한번 쓰기 작업 후 다시 쓰기를 진행해야 하는 등 데이터가 변경될 때마다 CPU와 I/O에 부하가 발생합니다. 다만, SSD 티어링을 사용하면 쓰기 부하를 어느정도 완화할 수는 있습니다.
이외에도 split-mirror 스냅샷에 COW 방식을 결합한 copy-on-write with background copy 방식의 스냅샷도 있습니다. COW 스냅샷처럼 스냅샷 생성 시, 원본 데이터에 대한 포인터를 지정해 순간적으로 생성한 후, 백그라운드에서 스냅샷 공간으로 원본 데이터 전체를 복제하는 방식입니다. COW의 point-in-time 스냅샷이 가능하고, 데이터에 대한 접근성이 뛰어나는 등 각각의 장점을 가지고 있지만, CPU 오버헤드가 발생하는 등의 단점도 같습니다.
Redirect-on-write 스냅샷
Redirect-on-write(이하 ROW) 방식은 위의 COW 방식에 비해 스토리지와 CPU의 오버헤드를 줄일 수있는 스냅샷 방식입니다. 기존 COW 스냅샷과는 다르게 변경되는 데이터를 여분의 공간에 직접 쓰기를 진행해 복사-붙이기 과정 하나를 생략할 수 있습니다. 다시 말해, 이는 쓰기 요청(write) 발생 시 새로운 공간으로 쓰기 위치를 재지정(redirect)하는 것을 의미합니다.
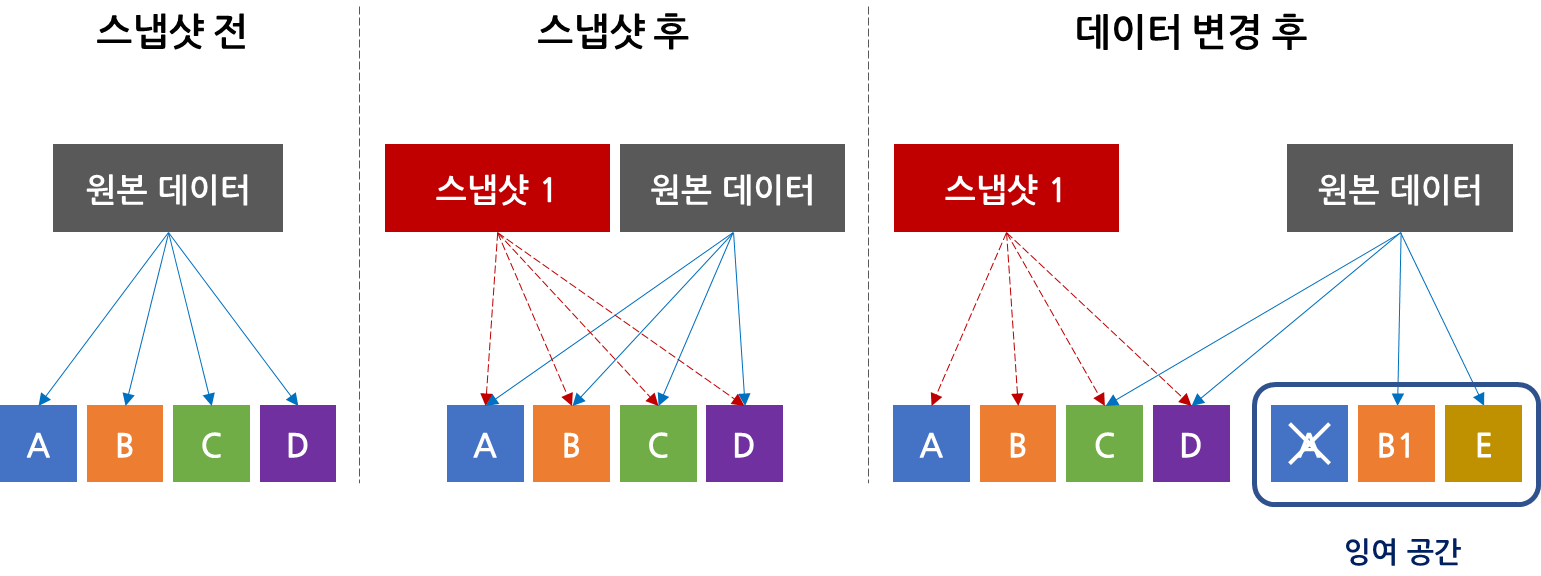
이해를 돕기 위해 위 그림과 같이 이전처럼 데이터 A와 B가 변경되고, 데이터 E가 생성되는 경우를 예시로 설명해 드리고자 합니다. 데이터 변경이 확인되면 삭제되는 데이터 A에 대한 정보와 변경되는 데이터 B, 그리고 추가되는 데이터 E를 여분의 공간에 바로 쓰기 작업을 진행합니다. 여기서 원본 데이터가 저장된 기존 공간은 그대로 스냅샷을 위한 공간이 됩니다.
이 방법은 COW와는 다르게(읽기 1회, 쓰기 2회) 새로 변경된 데이터의 쓰기 작업을 한번만 진행하면 되기 때문에 부하가 훨씬 덜 발생하게 됩니다. 이 때문에 최근에는 주류였던 COW 대신 ROW 스냅샷을 이용하는 경우가 많아지고 있습니다. 다만, 스냅샷을 삭제하는 경우 수정된 데이터의 포인터를 재설정하는데 추가적인 리소스 비용이 발생하게 됩니다. 또한, 스냅샷을 여러 개 생성할수록 포인터가 복잡해지는 경우가 있습니다.
증분 스냅샷
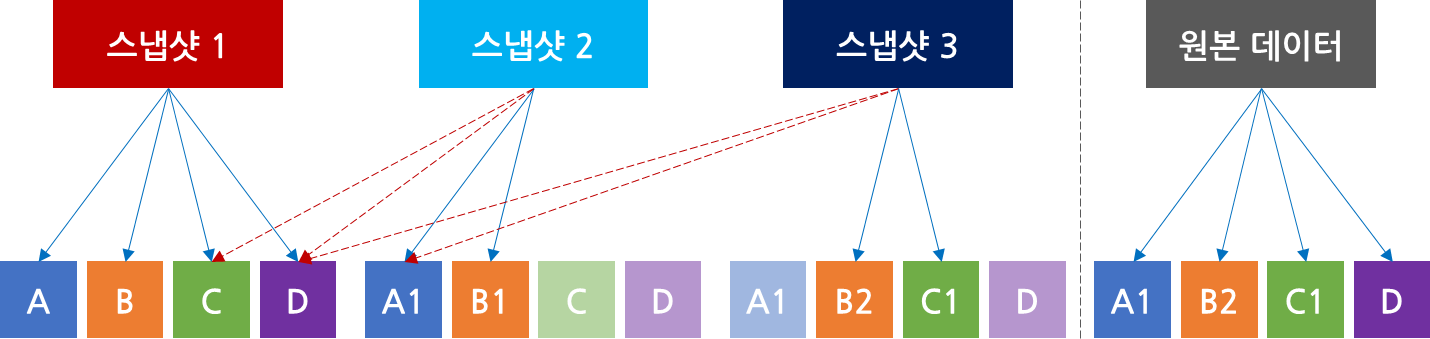
증분 스냅샷 (incremental snapshot)은 스냅샷 생성 이후에 변경되는 데이터만 새로운 스냅샷에 계속 기록하는 방식을 말합니다. 예를 들어, 위의 그림과 같이 스냅샷 1에 저장된 데이터 A, B, C, D에서 A와 B가 수정되었으면 수정된 A1과 B1이라는 데이터만 스냅샷 2에 저장합니다. 수정되지 않은 C와 D는 스냅샷 1에서 참조합니다. 스냅샷 3에서 B1과 C가 수정되면 스냅샷 3에는 수정된 데이터 B2와 C1만 저장되고, 나머지는 스냅샷 1과 2에서 참조합니다. 스냅샷을 생성할 때마다 스토리지 공간을 매우 적게 소모하기 때문에 다른 방식에 비해 스냅샷을 빠르고 자주 생성할 수 있습니다.
Continuous data protection
Continuous data protection(이하 CDP)은 데이터 블록이 수정될 때마다 자동으로 스냅샷을 생성하는 방식입니다. 일정 시간 단위로 스냅샷을 생성하는 기존의 point-in-time 방식과는 다르게, 수정한 가장 최근 지점까지 롤백이 가능하기 때문에 시스템 중단이 일어나기 직전의 데이터까지 확보할 수 있습니다. 다만, 변경이 가해질 때마다 스냅샷을 생성하기 때문에 필요 이상의 오버헤드가 가해질 수 있습니다.
스냅샷의 활용
스냅샷은 데이터 보호 방식 중에서도 가장 빠르고 많이 쓰이는 기능 중 하나입니다. 데이터를 따로 저장해 두고, 필요에 따라 복원하는 점은 일반적인 백업과 같지만, 스냅샷은 별도의 시스템이나 하드웨어 없이 보통 스토리지 공간 일부를 할애해 사용되기 때문에 저장과 복원을 더욱 빠르게 수행할 수 있습니다. 다만 저장공간의 한계로 스냅샷을 새로 생성할 때마다 오래된 스냅샷을 덮어씌우기 때문에 단기적인 백업 및 복구 용도로 사용할 수밖에 없습니다.

위에서 소개해 드린 CDP를 제외한 point-in-time 스냅샷의 경우, 일정 시간을 간격으로 스냅샷을 생성해 데이터 보호에 대비합니다. 스냅샷의 생성 주기가 짧으면 복구될 수 있는 데이터의 비율이 100%에 가까워지겠지만, 그만큼 성능과 스토리지 공간을 소모하게 됩니다. 또한 스냅샷 생성 시 작성되는 데이터의 양이 많거나 복잡도가 높을수록 장애로부터 복구하는데 시간이 더 걸릴 수 있습니다. 데이터 보호에 있어서 이처럼 데이터의 복구 수준과 데이터 복구 시간의 목표치를 각각 RPO(recovery point objective)와 RTO(recovery time objective)라고 합니다. 관리자들은 자신들의 IT 인프라의 특성을 파악해서 데이터 손실과 서비스 장애 시간을 최소화하기 위해 최적의 RPO와 RTO를 기준으로 스냅샷 방식을 선택해야 합니다.
마치며
앞서 말씀드린 바와 같이, 스냅샷을 생성하고 기록하는 방식은 매우 다양합니다. 관리자들은 스토리지 공간 효율이나 스토리지 I/O 및 CPU 워크로드 부하 등을 고려해 알맞은 스냅샷 방식을 도입해야 합니다. 관리자 입장에서 가장 이상적인 시나리오는 물론 모든 데이터를 복구할 수 있으면서 다운타임이 거의 없는 상황이겠지만, 시스템과 인프라 투자 비용의 한계로 적절한 타협 선을 강구해야 합니다.
참고
- https://en.wikipedia.org/wiki/Snapshot_(computer_storage)
- https://technoscooop.wordpress.com/tag/copy-on-write/
- https://www.computerweekly.com/feature/Storage-101-Snapshots-vs-backup
- https://searchdatabackup.techtarget.com/definition/storage-snapshot
- https://www.ibm.com/developerworks/tivoli/library/t-snaptsm1/index.html
- https://www.alibabacloud.com/help/doc-detail/25392.htm