스토리지 기초 지식 9편: 오브젝트 스토리지란
by 박주형 (jhpark@gluesys.com)
오늘날 인터넷 트래픽에서 오고 가는 데이터는 비정형 데이터가 주를 이루고 있습니다. 이력서 양식에 맞추어서 입력하는 신상 정보를 정형 데이터라 한다면, 비정형 데이터는 사진이나 자기 PR 텍스트, 첨부 동영상과 같이 규격 외의 데이터를 말합니다. 불과 2000년대 후반까지만 해도 비정형 데이터는 전체 데이터의 31%에 불과했으나1, 시장조사기관인 IDC에 의하면 2025년까지는 전체 데이터의 80%를 차지할 것으로 예상하고 있습니다. 게다가 이러한 대규모의 비정형 데이터는 클라우드 기술과 빅데이터 및 인공지능 분석 기술의 보편화로 그 쓰임새를 극대화하고 있습니다. 이 때문에 기존에 전통적인 스토리지를 운영하는 기업들은 이러한 비정형 데이터를 쉽게 저장하고 빠르게 검색할 수 있는 스토리지 아키텍처가 필요하게 되었고, 이로 인해 오브젝트 스토리지(object storage)가 주요 스토리지 중 하나로서 급부상하게 되었습니다.
블록, 파일, 그리고 오브젝트
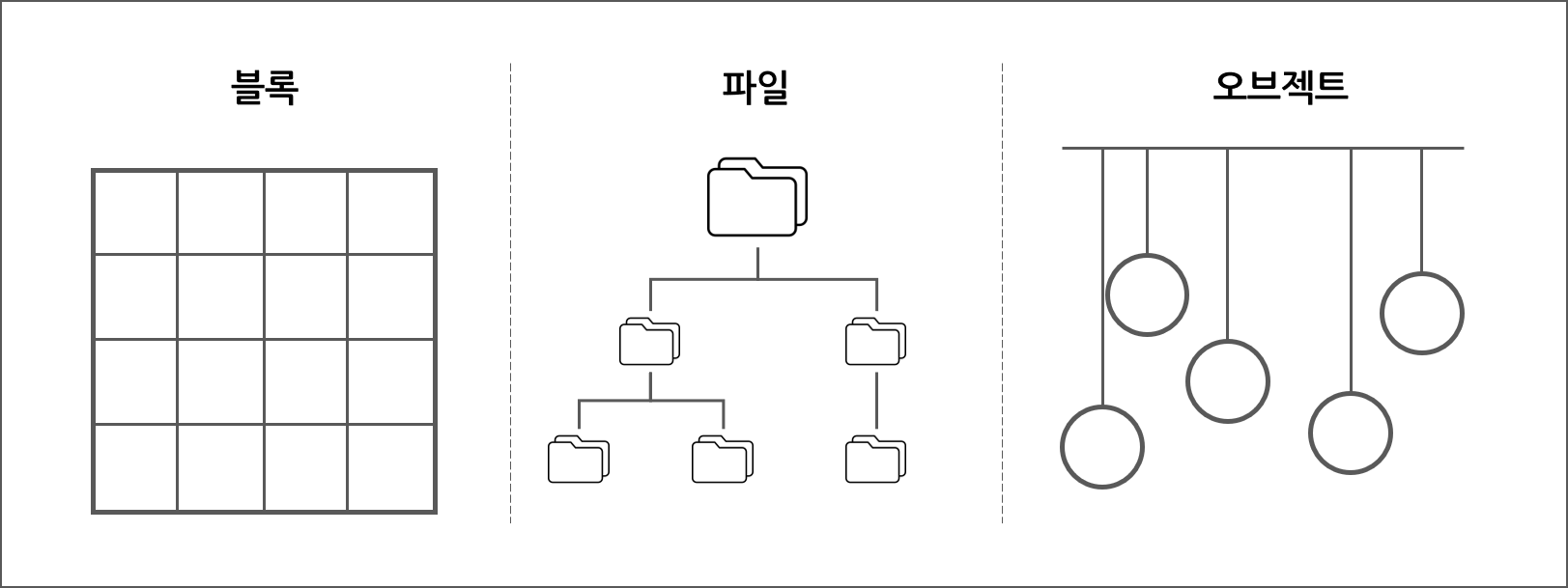
오브젝트의 개념을 쉽게 이해하기 위해 블록과 파일의 저장방식에 대해 먼저 짚고 넘어가 보고자 합니다. 우선 블록 저장방식의 경우, 데이터를 블록이라는 고정된 크기의 단위로 나뉘어 스토리지에 저장합니다. 각 블록은 블록이 저장된 위치를 가리키는 고유의 주소를 가지고 있어 주소만 알고 있으면 분산 저장된 데이터를 찾아 하나의 데이터로 재구성합니다. 파일 시스템 내 파일의 경우, 디렉토리(윈도우의 경우 폴더)에 저장되며, 윈도우 탐색기와 같은 계층형 구조로 구성되어 있습니다. 파일마다 파일의 위치, 크기, 생성일, 블록 위치 등에 대한 정보를 가지는 메타데이터를 가지고 있어 파일을 검색하거나 수정할 시 OS 내 파일 시스템이 해당 작업을 지원합니다. 이처럼 블록 스토리지가 데이터를 블록으로 나누어 관리하고 파일 시스템이 데이터를 계층형 구조의 파일에 저장하는 반면, 오브젝트 스토리지는 데이터를 오브젝트(Object)라는 단위로 관리합니다.
오브젝트에는 데이터와 그 데이터의 식별번호, 그리고 메타데이터가 포함됩니다. 데이터가 오브젝트 스토리지에 저장되면, 그 데이터에 범용 고유 식별자(Universally Unique Identifier, UUID)라는 128비트 정수로 구성된 식별번호가 부여됩니다. 이 고유의 식별번호를 통해 하나의 스토리지 풀 내에서 해당 오브젝트를 바로 찾을 수 있어 빠르게 데이터를 검색할 수 있습니다. 오브젝트는 폴더 속의 폴더의 연속인 파일 시스템과는 달리 평면적인(flat) 저장 방식이라고 볼 수 있습니다.
오브젝트 스토리지의 메타데이터는 파일 시스템과는 달리 데이터 관리와 인덱싱하기 편하도록 매우 다양하고 방대한 정보를 담을 수 있습니다. 파일 시스템의 메타데이터는 파일의 종류나 이름, 생성일 등에 한정되어 있지만, 오브젝트의 메타데이터는 커스터마이징이 가능하다는 점이 특징입니다. 메타데이터의 커스터마이징이 가능하다는 것은 사용자가 원하는 유형의 메타데이터를 정의할 수 있다는 뜻으로, 데이터의 종류나 용도와 관련된 정보나 데이터의 보호 수준까지 포함시킬 수 있습니다. 오브젝트의 이러한 특성은 빅데이터 분석에 매우 최적화되어 있다고 할 수 있습니다. 예를 들어, CCTV 영상에 해당 영상의 이름이나 찍힌 날짜뿐만 아니라 카메라 번호, 위치 정보, 이벤트 발생 시간 북마크 등의 메타데이터를 수집해 영상 검색에 활용하거나 해당 지역의 이벤트 발생 빈도 분석 등에 활용될 수 있습니다.
오브젝트 스토리지와 파일 스토리지의 비교
오브젝트 스토리지 아키텍처에서는 오브젝트가 평면적으로 저장되기 때문에 뛰어난 확장성을 가지게 됩니다. 전통적인 파일 시스템은 이러한 데이터의 성장에서 일부분 한계를 보이기도 합니다. 기존의 파일 시스템은 사용자가 파일을 검색하는 동안 해당 계층형 구조를 캐싱해야 하는데, 파일이 많을수록 이를 구현하는데 메모리의 리소스를 많이 소모하기 때문입니다. 이 때문에 페타바이트 규모의 환경에서는 최대 용량을 달성하기 전에 성능적 제약이 발생하고, 이를 피하기 위해서는 데이터를 다른 시스템으로 분산시켜야 하는 문제가 발생합니다.
분산 파일 시스템 기반 스토리지의 경우, 앞서 소개된 전통적인 파일 시스템의 한계를 어느 정도 해소할 수 있습니다. 분산 파일 시스템을 기반으로 하는 스케일아웃 NAS는 기존의 파일 시스템과는 달리 여러 노드에서 단일 네임스페이스를 가질 수 있습니다. 또한, POSIX(Portable Operating System Interface)를 지원해 기존 어플리케이션들과 호환성을 제공하고 파일 잠금(file locking) 기능을 지원해 공유 파일 수정 시 충돌을 방지할 수 있습니다. 스케일아웃 NAS는 주로 온프레미스 환경에서 비정형 데이터를 위한 고성능 스토리지로서 활용되어 왔으며, 클라우드 티어링 기술로 퍼블릭 클라우드 스토리지를 액티브 아카이브나 백업용 스토리지로 활용해 하이브리드 클라우드 환경을 구성하는 경우가 늘고 있습니다.
사실 오브젝트 스토리지는 성능 면에 있어서 구조가 단순하다는 점과 읽기 속도가 빠르다는 점을 제외하고는 파일 기반 스토리지에 비해 몇 가지 단점이 있습니다. 우선, 기본적으로 메타데이터의 규모로 인해 입출력에서 오버헤드가 발생하게 됩니다. 또한, 오브젝트는 데이터를 블록 단위로 나누어 저장하는 방식이 아니라 단일 구성으로 저장되기 때문에 데이터를 조금이라도 수정하게 될 경우 오브젝트 전체를 수정해야 합니다. 이 때문에 소규모의 데이터 수정이 빈번하게 일어나는 환경에서는 비효율적입니다. 게다가 환경 구성에 따라 성능이 일관적이지 않습니다. 클러스터의 크기나 클러스터 내 오브젝트를 저장한 위치에 대한 해시 테이블 알고리즘에 따라 다른 성능을 보입니다.

오브젝트 스토리지의 활용
오브젝트 스토리지 내 오브젝트는 API(Application Programming Interface)를 통해서 접근할 수 있습니다. 오브젝트 스토리지는 기본적으로 HTTP 기반의 RESTful API를 지원해 네트워크 상에서 오브젝트에 HTTP 명령어(PUT, GET, DELETE)를 사용할 수 있습니다. 이를 통해 웹 어플리케이션이 API를 통해 오브젝트 스토리지의 데이터에 직접적으로 접근할 수 있게 되고, 데브옵스(DevOps) 환경을 구성할 수 있게 되었습니다. 이러한 배경은 현재 클라우드 스토리지 환경이 오브젝트 기반으로 구성되는데 가장 큰 역할을 하게 되었습니다. 클라우드 스토리지로 가장 많이 쓰이는 벤더는 Amazon Web Service S3, Microsoft Azure, Google Cloud Storage 등이 있습니다.
오브젝트 스토리지의 가장 많은 사용처 중 하나는 주로 대규모 비정형 데이터에 낮은 빈도로 접근하는 환경입니다. 예를 들어, 영상 편집 환경에서 거대한 무수정 미디어 파일이나 편집 후 미디어 파일의 경우, 매우 큰 용량을 차지하면서 나중에 필요할 때 꺼내 써야 하는 경우가 있습니다. 기존에는 이와 같은 콜드 스토리지 역할을 테이프 라이브러리나 하드디스크 기반의 DAS를 사용해 왔지만, 유지비나 접근성을 고려해 액티브 아카이브 용 스토리지로써 오브젝트 스토리지를 채택하고 있습니다.
몇몇 분산 파일 시스템은 오브젝트 기반의 구조를 가지는 경우가 있습니다. 파일이 오브젝트 스토리지에 저장되고 그 파일의 메타데이터가 메타데이터 서버에 저장되는 방식으로, REST 기반 API만 지원하는 것을 넘어 블록과 파일 기반 프로토콜 또한 지원합니다. 오브젝트 기반 분산 파일 시스템은 아파치 재단에서 개발한 HDFS(Hadoop Distributed File System)와 오픈소스인 Ceph 등을 예로 들수 있습니다. HDFS는 많은 기업에서 사용되고 있는 대중적인 파일 시스템으로, x86 범용 하드웨어로 고확장 스토리지 환경을 구축할 수 있다는 점에서 각광받아 왔습니다. 다만 HDFS는 클러스터 마다 파일 시스템 네임스페이스가 하나 밖에 없어 메타데이터의 확장에 한계가 있습니다. Ceph은 블록, 파일, 오브젝트를 하나의 통합 시스템에서 제공하는 분산 파일 시스템입니다. HDFS와는 달리 메타데이터 서버를 여러 노드에 분산시켜 높은 성능과 확장성을 제공하고, POSIX를 지원해 레거시 어플리케이션과 높은 호환성을 보장합니다.
마치며
초기 DAS 시절부터 존재했던 블록 스토리지나 1990년대 NFS/CIFS를 기반으로 본격적으로 보편화된 NAS에 비해, 오브젝트 스토리지의 개념 자체가 등장한 것은 20년 정도 밖에 안됩니다. 비록 아직까지는 오브젝트 스토리지가 전통적인 SAN이나 NAS에 비해 작은 시장규모를 가지고 있다고는 하지만, 클라우드 연동성과 확장성, 메타데이터의 유연성 등을 고려했을 때 가파르게 성장하는 비정형 데이터를 담기에는 최적의 스토리지 중 하나라고 할 수 있습니다.
참고
- https://www.computerweekly.com/feature/Storage-pros-and-cons-Block-vs-file-vs-object-storage
- https://www.computerweekly.com/feature/Five-key-points-about-unstructured-data-storage-on-prem-and-cloud
- https://en.wikipedia.org/wiki/Object_storage
각주
-
https://tdwi.org/articles/2007/09/05/unstructured-data-attacking-a-myth.aspx ↩