NVMe 2.0: 키-값(Key-Value) 명령어 집합
by 김 성은(plumno1@gluesys.com)
안녕하세요! NVMe 관련 포스트를 추운 겨울에 썼던 것 같은데 벌써 뜨거운 여름이 되었네요. 꽤 긴 시간이 지난 만큼 그사이에 NVMe 2.0이 출시됐습니다! 그런 만큼 이번 포스트는 NVMe 2.0에서 새로 추가된 새로운 기능, 그중에서도 키-값 명령어 집합(Key-Value Command Set)를 메인으로 다루어 보도록 하겠습니다.
키-값 명령어 집합(Key-Value Command Set)
키-값 데이터베이스(Key-Value Database)
키-값 명령어를 사용하는 SSD에 대해 알아보기 전에 먼저 키-값 데이터베이스에 관해 설명하겠습니다.
키-값 데이터베이스는 연관 배열(Hash), 사전(Dictionary)과 같은 자료 구조처럼 어떤 키를 사용하여 데이터베이스에 저장된 값을 찾아내는 방식의 데이터베이스입니다. 이때 키는 테이블별로 고유한 값을 지니고 있습니다. 예전에는 관계형 데이터베이스에 밀려 잘 쓰이지 않았다고 합니다. 하지만 정형 데이터밖에 넣을 수 없는 관계형 데이터베이스보다 비정형 데이터를 저장할 수 있는 특징 덕분에 근래에는 많이 사용되고 있다고 합니다.
배경
키-값 명령어들이 새로 나오게 된 배경에는 위에서 잠깐 언급 드렸지만 최근 정형 데이터보다 비정형 데이터를 많이 저장하게 되었다는 것에 있습니다. 기존의 블록 저장 장치를 사용하는 경우, 키와 논리 블록 주소(Logical Block Address, 이하 LBA)를 변환하는 별도의 소프트웨어가 필요하게 되는데, 그러면 만들어져 있는 키-값 데이터베이스 소프트웨어를 사용하지 않고 새로운 명령어까지 만든 이유는 무엇일까요? 그 이유는 이제 SSD 하드웨어 자체를 키-값 데이터베이스로 사용할 수 있도록 만들었기 때문입니다.
이런 놀라운 기술을 만들 수 있었던 그 배경에는 이름 공간(Namespace)이 있었다고 합니다. NVMe 2.0에서 새로 출시된 기능인 Namespace Types로 각 이름 공간의 특수한 접근 방법을 설정할 수 있게 되었습니다. 이것으로 인하여 각각의 이름 공간을 하나의 테이블처럼 사용할 수 있게 되었습니다.
기능
이번에는 어떤 명령어들이 있는지 알아보겠습니다.
먼저 저장(Store) 입니다. 저장 명령어는 SSD에 주어진 키와 값으로 데이터를 저장하는 명령어입니다. 새로 저장되는 데이터(값)를 압축(compress)/비압축(raw) 설정, 덮어쓰기(수정) 금지, 해당 키로는 값을 저장하지 않도록 생성 금지 명령 등이 가능합니다. 중요한 명령인 만큼 데이터베이스에서 트랜잭션처럼 원자성(atomicity)을 띠고 있습니다.
다음은 검색(Retrieve) 입니다. 검색 명령어는 주어진 키로 값을 찾아주는 명령어입니다. 압축된 값을 압축 해제하여 검색, 비압축 검색도 가능하며 검색된 값의 길이(바이트 단위)도 검색 결과로 볼 수 있습니다. 키로 검색을 하는 만큼 키를 알고 있어야 데이터(값) 검색이 가능하겠죠? 하지만 모든 키를 전부 기억하실 필요는 없습니다.
이런 경우에는 조회(List) 명령을 사용하여 해당 이름 공간에 존재하는 모든 키들을 검색할 수 있습니다. 하지만 항상 모든 키를 검색할 필요가 없을 수도 있을 겁니다.
그럴 때는 존재(Exist) 명령을 사용하면 해당 키가 있는지 없는지 알 수 있습니다. 이때 반환되는 값은 키를 찾으면 0x00을 반환하고 찾지 못했다면 입력받았던 키를 다시 반환합니다.
저장, 검색이 나왔으니 한 가지만 더 나오면 될 것 같습니다. 삭제(Delete) 명령입니다. 주어진 키와 키에 연관된 값을 삭제하는 명령입니다. 이 명령도 저장과 마찬가지로 중요한 명령인 만큼 원자성을 띠고 있습니다.
여기서 주의할 점은 키는 최대 16 바이트에서 최소 1 바이트 길이를 가지는 가변적인 값이며, 단위는 1 바이트라는 것입니다. 또한 키는 길이가 다르면 서로 다른 키로 인식됩니다. 예를 들어 16진수 0x55와 0x0055는 서로 다른 키로 인식됩니다.
값은 최대 4GB의 크기를 가질 수 있으며 길이가 0일 수도 있습니다. 즉 키만 있고 값은 아무것도 없는 데이터도 저장할 수 있습니다.
여기서 설명한 명령어들은 전부 이번 NVMe 2.0에서 출시된 NVMe 키-값 명령어 1.0 버전에서 명시된 필수 명령어들입니다. 이렇게 보니 충분히 하드웨어만으로도 데이터베이스를 만들 수 있을 것 같다는 생각이 드네요.
구조

위 그림은 기존 블록 저장장치와 키-값 SSD의 구조를 보여주는 그림입니다. 여기서 바뀐 구조로 입출력을 하는 과정은 아래 그림과 같습니다.
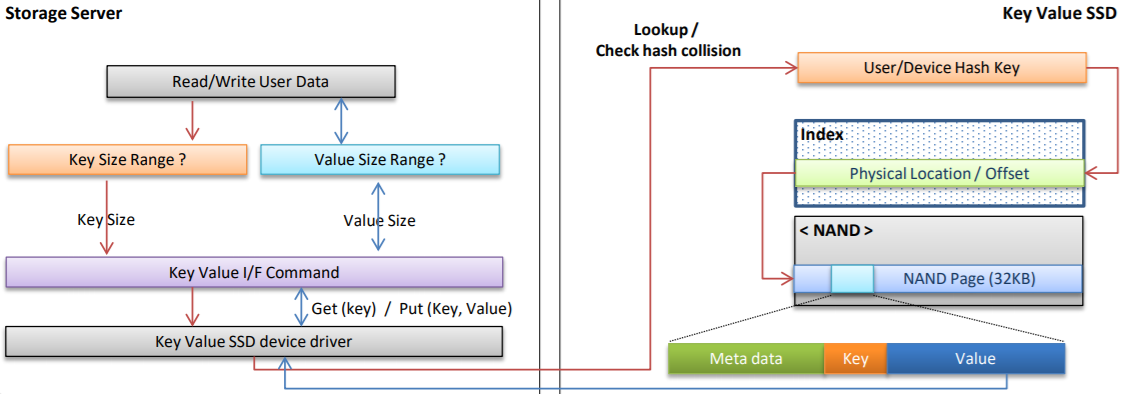
위 그림들에서 알 수 있듯이 기존의 블록 저장장치와 매우 큰 차이점이 있습니다. 바로 주소를 사용하지 않는다는 점입니다. 이 점으로 인해 키-값 구조 그림처럼 사용자가 요청한 명령을 키-값 데이터베이스에서 가져오도록 요청하고 그 요청을 받은 데이터베이스는 파일 시스템에서 해당 데이터가 블록 저장장치의 어디 주소에 저장되어 있는지 변환하는 과정을 없앨 수 있었습니다. 이 과정으로 인해 프로비저닝 오버헤드가 사라졌다고 합니다. 뭔가 어려운 말 같지만 풀어 말하면 “논리 주소를 사용하지 않기 때문에 물리 주소와 논리 주소를 매핑해둘 필요가 없고, 사용 가능한 주소의 범위는 SSD의 물리적인 용량으로 결정되는 것이 아니라 사용 가능한 총 키의 개수로 결정되기 때문에 기존의 SSD보다 예비용 저장공간을 줄일 수 있다.”라는 뜻입니다.
키-값 저장장치 소프트웨어 개발 스택
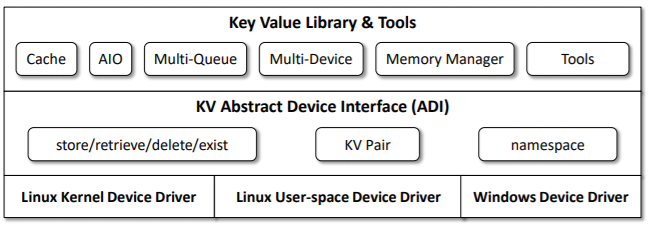
조금 어려운 내용이 나왔습니다. 위 그림은 키-값 SSD를 만들 때 필요한 구성요소입니다. 각 층에 관해 설명하겠습니다. 먼저 가장 아래층인 장치 드라이버들입니다. 아무래도 새롭게 만들어지는 장치이다 보니 필요한 드라이버들에 관한 내용이 있습니다. 여기에는 새로운 명령어들과 새로운 기능들이 추가됩니다. 그 위층인 KV Abstract Device Interface에는 기본적으로 이 장치가 제공해야 하는 기능들이 담겨 있습니다. 위에서 설명했던 기본 명령어들이나 이름 공간 제어 등이 여기에 속합니다. 마지막으로 Key Value Library & Tools입니다. 여기에는 이보다 아래의 스택들을 사용하기 위해 버려야 했던 기능들을 도구나 라이브러리의 형태로 제공합니다. 예를 들어 파일 시스템을 사용하지 않기 때문에 파일 시스템에서 제공하는 페이지 캐시 기능을 받지 못합니다. 이런 형태의 불편함을 줄이기 위한 기능들이 여기에 속합니다.
장점
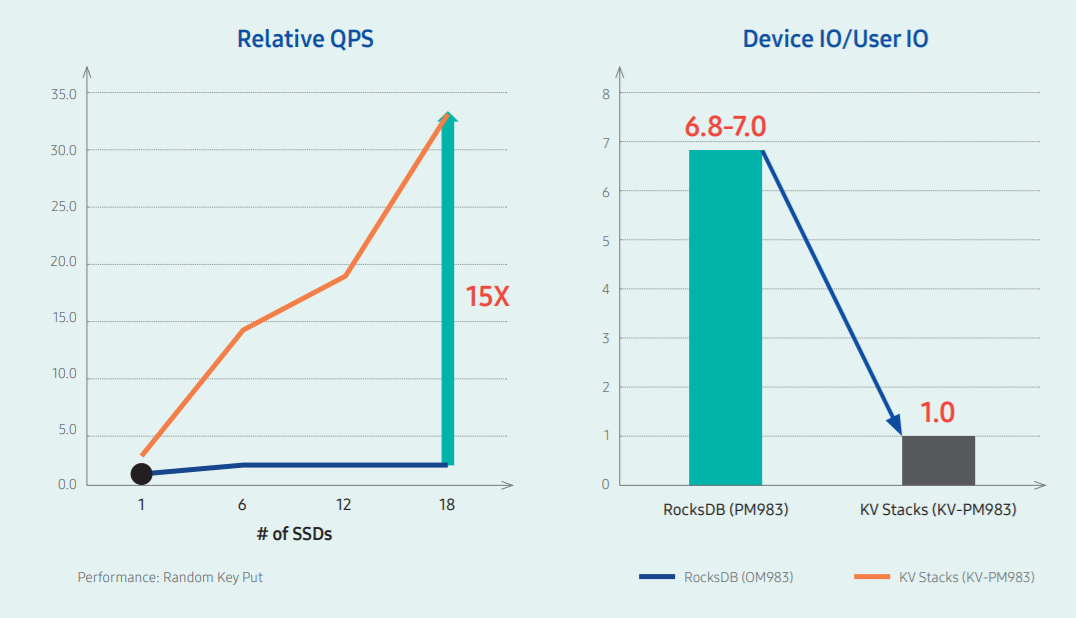
위 그림은 일반 블록 저장장치에 키-값 데이터베이스를 설치한 것과 키-값 SSD의 임의 쓰기 시 QPS(Queries Per Second, 데이터베이스에서 1초 동안 수신하는 요청 수)를 비교한 것으로, 1.2테라바이트의 데이터로 SSD 24개에 임의의 키를 입력 시켜 그 속도를 측정했습니다. 우선 오른쪽 그래프를 보시면, 블록 저장장치를 사용한 Rocks DB는 6개 이상의 SSD에 쓰기 명령을 내렸을 때부터 쓰기 증폭1으로 인한 과부하가 일어나는 것으로 보입니다. 그러나 키-값 SSD는 18개에 쓰기 명령을 내려도 멀쩡하네요. Device IO/User IO는 쓰기 증폭 값을 나타내는 것인데 약 7배가량 차이가 나는 것으로 보입니다. 왼쪽 그래프를 보시면, 이 그래프에는 18까지 밖에 나오지 않았지만, CPU 코어의 수와 같은 수의 키-값 SSD를 사용하면 일반 블록 저장장치보다 약 15배의 QPS 차이가 난다고 합니다. 이처럼 키-값 명령어를 사용하는 SSD는 키-값 데이터베이스로 사용했을 때 일반 SSD보다 더 큰 용량과 빠른 성능을 보이는 강점이 있습니다.
키-값 저장장치 vs 오브젝트 스토리지
비정형 데이터를 저장하는 데에 있어 둘이 비슷한 점을 가지고 있긴 하지만 그 외에는 전혀 다른 장치라고 할 수 있습니다. 먼저 키-값 저장장치는 블록 저장장치가 아니라는 것 입니다. 앞서 말씀드렸듯이 가변 길이의 키를 주소로 사용하여 데이터를 저장하는 방식을 사용합니다. 반면에 오브젝트 스토리지는 블록 저장장치에 고정된 길이의 오브젝트 구분자를 사용하여 저장합니다. 또 키와 값, 오브젝트와 오브젝트 구분자를 각각 매핑하는 주체도 키-값 저장장치에서는 스토리지(하드웨어) 그 자체가 키와 값을 서로 매핑하지만 오브젝트 스토리지는 프로토콜(소프트웨어)이 오브젝트 구분자와 오브젝트를 매핑하는 주체가 됩니다.
그런데 Ceph에서 키-값 저장장치를 오브젝트 스토리지로 사용할 수 있도록 오픈소스 소프트웨어를 만들었습니다. 이제 오브젝트 스토리지는 블록 저장 장치만을 사용한다는 말은 틀린 말이 되어버렸네요.
이렇게 NVMe 2.0에서 새롭게 출시된 기능 중 하나인 키-값 명령어에 대해 알아보았습니다. 하드웨어 자체를 데이터베이스로 사용하도록 만든다는 자체가 신기하게 다가와서 공부하면서도 재미있었던 것 같네요! 다음엔 어떤 신기한 기술들이 나올지 생각해보면서 이번 포스팅은 여기서 마치도록 하겠습니다~
참고
- https://github.com/OpenMPDK/KVCeph
- https://www.samsung.com/semiconductor/global.semi.static/Samsung_Key_Value_SSD_enables_High_Performance_Scaling-0.pdf
- https://www.snia.org/sites/default/files/SDC/2017/presentations/Object_ObjectDriveStorage/Ki_Yang_Seok_Key_Value_SSD_Explained_Concept_Device_System_and_Standard.pdf
-
쓰기 증폭(Write Amplification, WAF) : 덮어쓰기가 불가능한 플래시 메모리 구조 때문에 생기는 현상으로 해당 위치에 덮어쓰기 할때 원래 있던 데이터를 다른곳에 옮기고, 해당 위치의 데이터를 삭제하고 다시 쓰는것, 이 값이 크면 클수록 속도저하도 커짐 ↩