Lustre 파일시스템과 GPUDirect Storage 소개
by 권세훈 (qsh700@gluesys.com)
Lustre 파일시스템과 GPUDirect Storage 소개
이번 장에서는 고성능 컴퓨팅(High Performance Computing, 이하 HPC) 클러스터에서 사용될 러스터 파일시스템(Lustre File System)과 GDS(GPUDirect Storage)에대해 간략하게 알아보겠습니다.
먼저 HPC 클러스터는 고도의 컴퓨팅 성능이 필요한 환경으로, 대규모의 애플리케이션들이 많은 양의 데이터를 처리합니다. 개발자는 HPC 애플리케이션 개발을 위해 병렬 처리를 위한 표준 라이브러리인 MPI(Message Passing Interface)를 이용하거나, MapReduce, Spark 등의 병렬 처리 프레임워크를 사용했습니다. HPC 클러스터는 컴퓨팅 성능 외에도 대규모의 데이터를 다룰 수 있는 병렬 스토리지를 필요로 합니다. 대표적으로 병렬/분산 스토리지 분야에서 구글(Google)의 GFS(Google File System)와 이를 모티브한 오픈 프로젝트인 HDFS(Hadoop Distributed File System)등이 있지만, 두 프로젝트 모두 대용량의 데이터를 저장하는데 초점이 맞춰있습니다. HPC 클러스터 환경은 이보다 작은 규모의 스토리지 환경에서 다수의 애플리케이션이 실시간으로 데이터에 동시 접근하기 때문에 보다 빠르고 더 작은 크기의 입출력 처리를 요구합니다.
러스터를 알아보기에 앞서 분산 파일시스템과 병렬 분산 파일시스템의 차이를 알아보겠습니다.
병렬 분산 파일시스템
분산 파일시스템은 단일 스토리지 노드에 파일을 저장하는 반면 병렬 파일시스템은 일반적으로 파일을 분할하고 여러 스토리지 노드에 데이터 블록을 나누어 저장합니다. 메타데이터는 일반적으로 효율적인 파일 조회를 위해 별도의 메타데이터 서버에 저장되는 반면에 분산 파일시스템은 표준 네트워크 파일 액세스를 사용하며 전체 파일 데이터와 메타데이터를 단일 스토리지에서 컨트롤러에 의해 관리됩니다. 대역폭을 많이 사용하는 워크로드의 경우 이러한 단일 액세스 지점이 성능의 병목 현상이 됩니다. 러스터 병렬 파일시스템은 이러한 단일 컨트롤러 병목 현상을 겪지는 않지만, 병렬 액세스를 제공하는데 필요한 아키텍처가 상대적으로 복잡합니다.
러스터 파일시스템
러스터(Lustre)는 분산 파일시스템의 한 유형인 병렬 파일시스템으로 주로 HPC의 대용량 파일시스템으로 사용되고 있습니다. 러스터는 GNU GPL 정책의 일환으로 개방되어 있으며 소규모 클러스터 시스템부터 대규모 클러스터까지 사용되는 고성능 파일시스템입니다. 높은 성능과 코드가 개방되어있어서 슈퍼컴퓨터에 자주 사용됩니다. 우리나라에서는 한국과학기술정보연구원과 기상청이 러스터 파일시스 기반 스토리지를 사용하고 있습니다. 러스터는 리눅스 기반 운영체제에서 실행되며 클라이언트(Client)-서버(Server) 네트워크 아키텍처를 사용합니다. 러스터라는 이름의 유래는 Linux와 Clustre의 혼성어로 탄생하였습니다.
- 러스터 파일시스템 아키텍처1
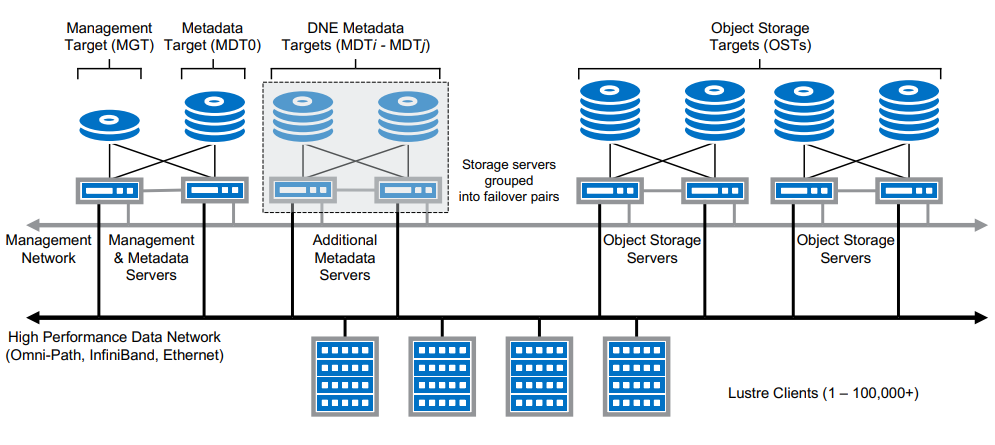
위 [그림 1]은 러스터 아키텍처를 표현한 것으로 각각의 구성 요소와 역할은 다음과 같습니다.
- MGS(Management Server)
- 모든 러스터 파일시스템에 대한 구성 정보를 클러스터에 저장하고 이 정보를 다른 러스터 호스트에 제공합니다.
- MGT(Management Target)
- 모든 러스터 노드에 대한 구성 정보는
MGS에 의해MGT라는 저장장치에 기록됩니다.
- 모든 러스터 노드에 대한 구성 정보는
- MDS(Metadata Server)
- 러스터 파일시스템의 모든 네임 스페이스를 제공하여 파일시스템의 아이노드(inodes)를 저장합니다.
- 파일 열기 및 닫기, 파일 삭제 및 이름 변경, 네임 스페이스 조작 관리를 합니다.
- 러스터 파일시스템에서는 하나 이상의
MDS와MDT가 존재합니다.
- MDT(Metadata Target)
MDS의 메타 데이터 정보를 지속적으로 유지하는데 사용되는 저장장치입니다.
- OSS(Object Storage Servers)
- 하나 이상의 로컬
OST에 대한 파일 서비스 및 네트워크 요청 처리를 제공합니다.
- 하나 이상의 로컬
- OST(Object Storage Target)
OSS호스트에 고르게 분산되어 성능의 균형을 유지하고 처리량을 최대화합니다.
- Lustre 클라이언트
- 각
클라이언트는 여러 다른 러스터 파일시스템 인스턴스를 동시에 마운트 가능합니다.
- 각
- LNet(Lustre Networking)
- 클라이언트가 파일시스템에 액세스하는데 사용하는 고속 데이터 네트워크 프로토콜입니다.
윗글에서는 러스터 파일시스템이 어떻게 구성되어 있는지 알아보았습니다. 다음으로는 러스터 파일시스템에서 중요하다고 생각되는 몇 가지 기술들을 알아보겠습니다.
HSM(Hierarchical Storage Management)
HSM은 고가의 저장매체와 저가의 저장매체 간의 데이터를 자동으로 이동하는 데이터 저장 기술입니다.
- HSM 아키텍처2
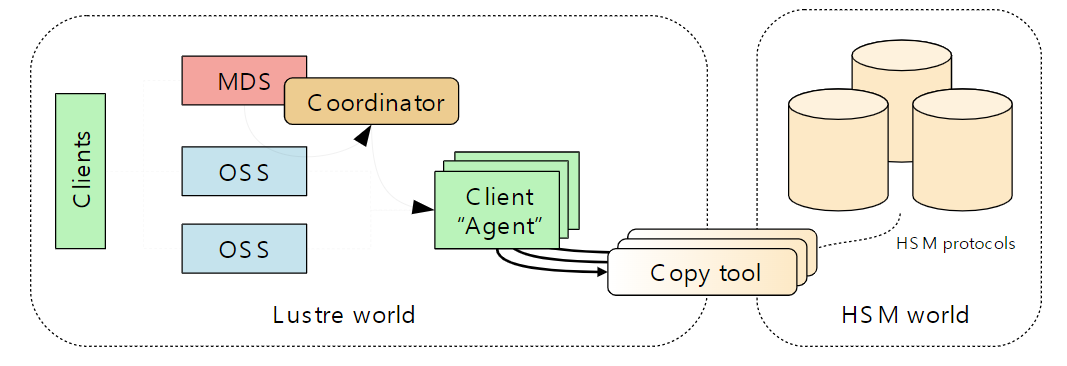
- 러스터 파일시스템을 하나 이상의 외부 스토리지 시스템에 연결할 수 있습니다.
- 파일을 읽기, 쓰기, 수정과 같이 파일에 접근하게 되면 HSM 스토리지에서 러스터 파일시스템으로 파일을 다시 가져옵니다.
- 파일을 HSM 스토리지에 복사하는 프로세스를
아카이브(Archive)라고 하고 아카이브가 완료되면 러스터 파일시스템에 존재하는 데이터를 삭제할 수 있습니다. 이것을릴리즈(Release)라고 말합니다. HSM 스토리지에서 러스터 파일시스템으로 데이터를 반환하는 프로세스를복원(restore)라 하고 여기서 말하는 복원과 아카이브는HSM Agent라는 데몬이 필요합니다. 에이전트(Agent)는copytool이라는 유저 프로세스가 실행되어 러스터 파일시스템과 HSM 간의 파일 아카이브 및 복원을 관리합니다.-
코디네이터(Coordinator)는 러스터 파일시스템을 HSM 시스템에 바인딩하려면 각 파일시스템 MDT에서 코디네이터가 활성화되어야 합니다. - HSM과 러스터 파일시스템간의 데이터 관리 유형은 5가지의 요청으로 이루어집니다.
archive: 러스터 파일시스템 파일에서HSM솔루션으로 데이터를 복사합니다.release: 러스터 파일시스템에서 파일 데이터를 제거합니다.restore: HSM 솔루션에서 해당 러스터 파일시스템으로 파일 데이터를 다시 복사합니다.remove: HSM 솔루션에서 데이터 사본을 삭제합니다.cancel: 진행 중이거나 보류 중인 요청을 삭제합니다.
PCC(Persistent Client Cache)
- PCC 아키텍처3
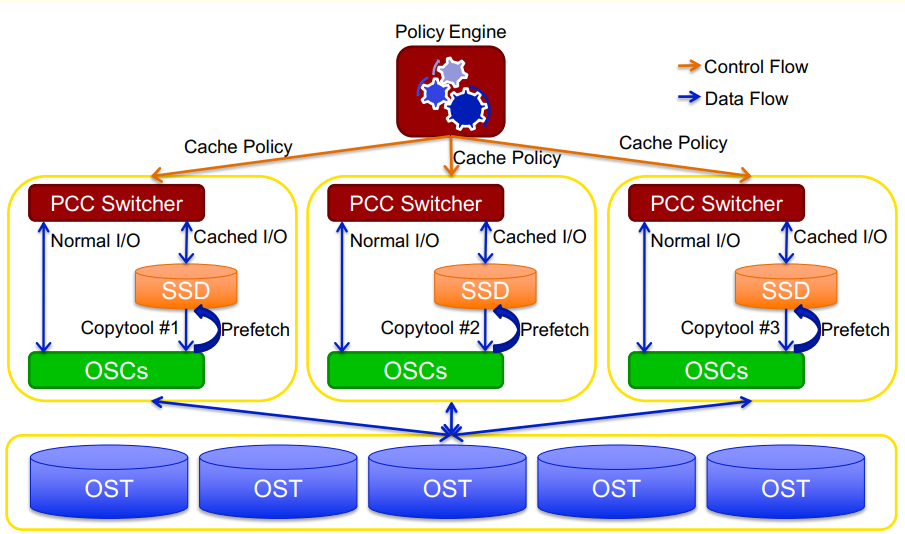
PCC는 러스터 클라이언트 측에서 로컬 캐시 그룹을 제공하는 프레임워크입니다. 각 클라이언트는 OST 대신 로컬 저장장치를 자체 캐시로 사용합니다. 로컬 파일시스템은 로컬 저장장치 안에 있는 캐시 데이터를 관리하는 데 사용됩니다. 캐시 된 입출력의 경우 로컬 파일시스템으로 전달되어 처리되고 일반 입출력은 OST로 전달됩니다.
PCC는 데이터 동기화를 위해 HSM 기술을 사용합니다. HSM copytool을 사용하여 로컬 캐시에서 OST로 파일을 복원합니다. 각 PCC에는 고유한 아카이브 번호로 실행되는 copytool 인스턴스가 있고 다른 러스터 클라이언트에서 접근하게 되면 데이터 동기화가 진행됩니다. PCC가 있는 클라이언트가 오프라인 될 시 캐시 된 데이터는 일시적으로 다른 클라이언트에서 접근할 수 없게 됩니다. 이후 PCC 클라이언트가 재부팅되고 copytool이 다시 동작하면 캐시 데이터에 다시 접근할 수 있습니다.
PCC 장/단점
- 장점
클라이언트에서 로컬 저장장치를 캐시로 이용하게 되면 네트워크 지연이 없고 다른 클라이언트에 대한 오버헤드가 없습니다. 또한, 로컬 저장장치를 입출력 속도가 빠른 SSD or NVMe SSD4를 통해 좋은 성능을 낼 수 있습니다. SSD는 모든 종류의 SSD가 사용가능하며, 캐시 장치로 이용할 수 있습니다. PCC를 통해 작거나 임의의 입출력을 OST로 저장할 필요 없이 로컬 캐시 장치에 저장하여 사용하면 OST 용량의 부담을 줄일 수 있는 장점이 있습니다.
- 단점
클라이언트 로컬에 저장장치를 추가하면서 구성이 복잡해질 수 있습니다. 고속 저장장치를 통해 좋은 성능을 낼 수 있지만, 비용적인 문제가 있을 수 있습니다.
오버스트라이핑(Overstriping)
- 스트라이핑과 오버스트라이핑 비교5
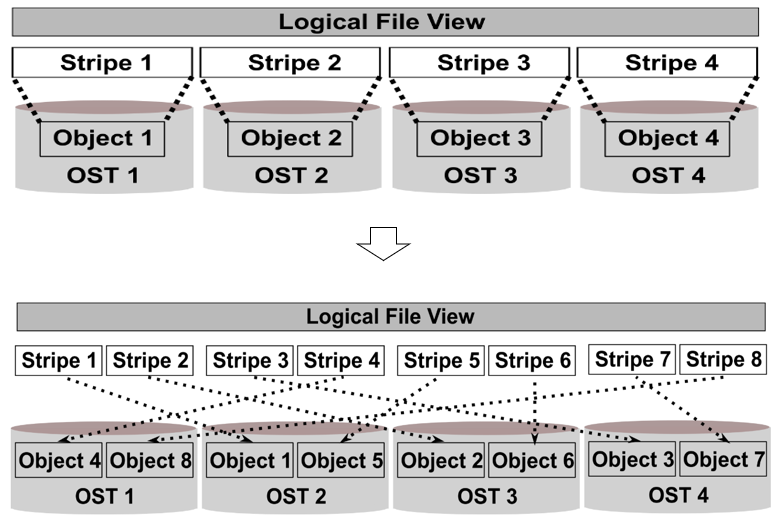
기존에는 OST당 스트라이프(stripe)가 하나였다면, 오버스트라이핑(Overstriping)은 OST당 여러 개의 스트라이프를 가질 수 있습니다. 기본적으로 스트라이프의 크기는 1MB(1048576 바이트)로 되어있습니다.
일반적으로 러스터에서는 스트라이프를 구성하기 전 순차적으로 OST에 저장되는 것을 확인할 수 있습니다. 스트라이프를 구성 후에는 각 OST마다 동등하게 분배되어 파일이 저장되는 것을 확인할 수 있습니다. 오버스트라이핑 같은 경우 아래 [그림 5]에서 볼 수 있듯이 일반 스트라이핑으로 구성한 것보다 빠르다는 장점이 있습니다.
다음은 일반 스트라이핑 구성과 오버스트라이핑을 구성하는 명령어입니다.
// Client에서 실행
// 스트라이핑 구성 명령어, --stripe-count, --overstripe-count 옵션에 이어서 디렉터리 또는 파일명을 입력합니다.
// OST가 4개일 때 4개의 스트라이프
[root@lzfs-client ~]# lfs setstripe --stripe-count 4 /mnt/stripe
// OST가 4개일 때 8개의 스트라이프
[root@lzfs-client ~]# lfs setstripe --overstripe-count 8 /mnt/overstripe
// stripe 구성 확인
[root@lzfs-client ~]# lfs getstripe /mnt/stripe
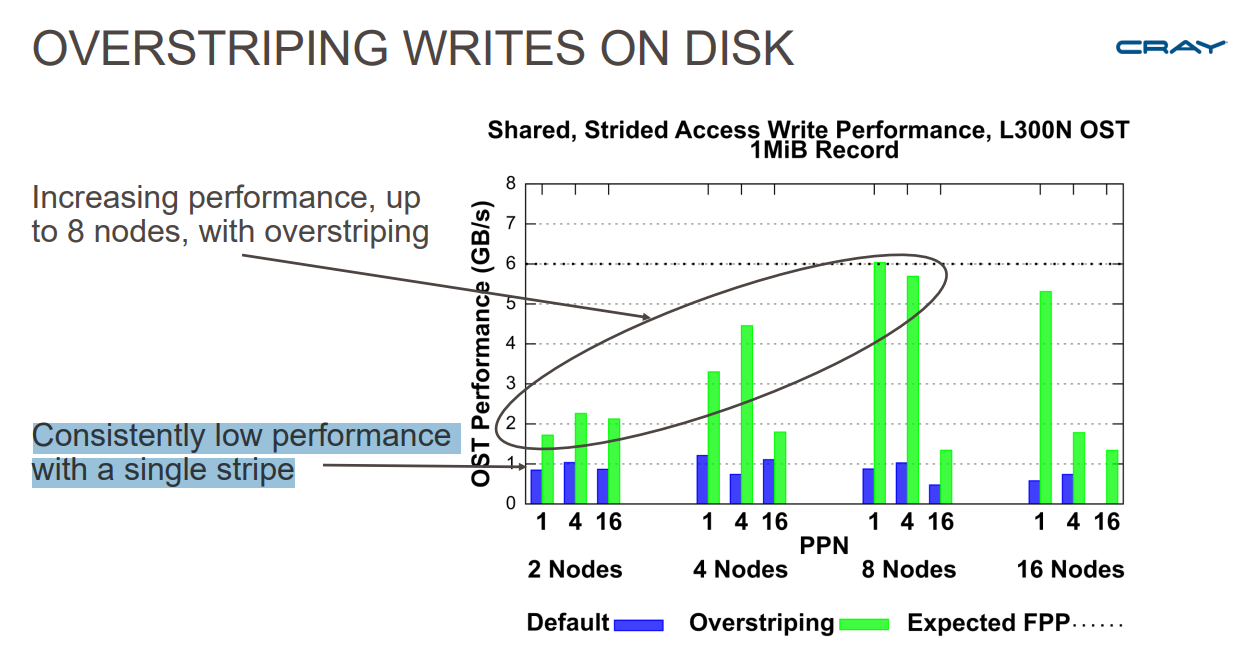
일반 스트라이핑 했을 때와 오버스트라이핑 성능 비교 6
[그림 5]에서 보시다시피, 일반 스트라이핑은 노드 수가 많아도 일관적으로 낮은 성능을 보이는 반면, 오버스트라이핑으로는 최대 8개 노드까지 성능 향상을 보이고 있습니다.
DoM(Data-On-MDT)
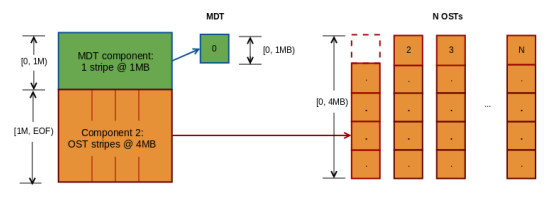
러스터 파일시스템은 현재 대용량 파일에 최적화되어 있습니다. 이로 인해 파일 크기가 너무 작은 단일 파일일 경우 성능이 크게 저하되는 문제가 있습니다. DoM은 작은 파일을 MDT에 저장하여 이러한 문제를 해결합니다. DoM을 이용해서 MDT에 작은 파일을 저장하였을 때 추가적으로 OST에 접근할 필요가 없어 작은 입출력에 대한 성능이 향상됩니다.
DoM은 두 가지 구성요소가 있습니다. 첫 번째는 MDT 컴포넌트 두 번째는 OST stripe로 구성됩니다. 기본적으로 DoM의 MDT stripe 크기는 1MB로 설정되어있습니다. 이를 변경하기 위해서는 다음과 같은 명령어를 사용합니다.
// MDS 서버에서 실행
// DoM 스트라이프 크기를 확인
[root@MDS ~]# lctl get_param lod.*.dom_stripesize
// DoM 스트라이프 크기를 2M로 변경
[root@MDS ~]# lctl get_param -P lod.*.dom_stripesize=2M
// DoM 스트라이프 크기 설정을 설정 정보에 저장
// conf_param 옵션에 이어서 러스터 구성때 사용한 fsname과 데이터가 저장될 MDT의 번호 다음에 lod.dom_stripesize=0을 입력합니다.
// (<fsname>-MDT0000.lod.dom_stripesize=0)
[root@MDS ~]# lctl conf_param lustre-MDT0000.lod.dom_stripesize=0
다음은 DoM을 구성했을 때 예제 그림과 이를 구성하는 명령어 입니다.
DoM 구성 예시7
[root@Client ~]# lfs setstripe <--component-end| -E end1> <--layout | -L> mdt [<--component-end| -E end2> [STRIPE_OPTIONS] ...] <filename>
ex) [root@Client ~]# lfs setstripe -E 1M -L mdt -E -1 -S 4M -c -1 /mnt/lustre/domfile // -S는 스트라이프 크기, -c는 스트라이프 개수
//구성 확인
[root@Client ~]# lfs getstripe /mnt/lustre/domfile
test2_domfile
lcm_layout_gen: 2
lcm_mirror_count: 1
lcm_entry_count: 2
lcme_id: 1
lcme_mirror_id: 0
lcme_flags: init
lcme_extent.e_start: 0
lcme_extent.e_end: 1048576
lmm_stripe_count: 0
lmm_stripe_size: 1048576
lmm_pattern: mdt
lmm_layout_gen: 0
lmm_stripe_offset: 0
lcme_id: 2
lcme_mirror_id: 0
lcme_flags: 0
lcme_extent.e_start: 1048576
lcme_extent.e_end: EOF
lmm_stripe_count: -1
lmm_stripe_size: 4194304
lmm_pattern: raid0
lmm_layout_gen: 0
lmm_stripe_offset: -1
DNE(Distributed Namespace Environment)
DNE 아키텍처8
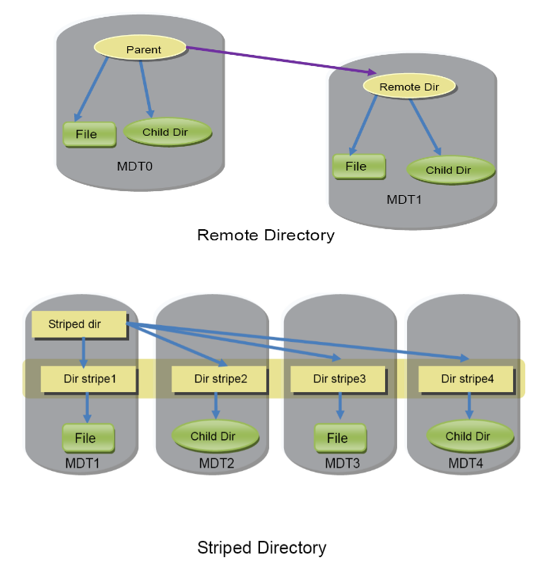
HPC 시스템은 일상적으로 수많은 클라이언트로 러스터를 구성합니다. 이렇듯 클라이언트가 확장되었을 때 MDT도 추가로 확장 되어야합니다. DNE는 MDT가 추가되었을 때 분배하는 방법에 대해 말하고 있습니다.
러스터 버전 2.4부터는 볼륨의 각 디렉터리 마다 MDT를 정해서 동시에 사용하는 원격 디렉터리(Remote Directory, Phase I, 1단계) 기능이 DNE 1로 소개되었으며, 버전 2.8 부터는 단일 디렉터리를 여러 개의 MDT로 분산시킬 수 있는 분산 디렉터리(Striped Directory, Phase II, 2단계) 기능 또한 DNE 2로 소개되었습니다. 이후 버전에서는 디렉터리 마이그레이션(Directory Migration), QoS 할당(QoS Allocation), 디렉터리 재분산(Directory Restripe, Phase III, 3단계) 기능을 추가하여 DNE 3으로 소개되고 있습니다.
1단계 - 원격 디렉터리
1단계인 원격 디렉터리에서 러스터 하위 디렉터리는 원격지의 다른 MDT에 배포될 수 있습니다. 하위 디렉터리 배포는 관리자가 lfs 명령줄 도구의 mkdir 하위 명령을 사용하여 만들 수 있습니다.
2단계 - 분산 디렉터리
2단계인 분산 디렉터리는 스트라이프 수가 존재하는데 이는 메타데이터를 저장할 MDT 수를 결정합니다. 하나의 MDT를 기준으로 단일 디렉터리를 만들어 정해진 MDT 수로 스트라이프 되어 저장하는 방식입니다. 이렇게 하면 단일 디렉터리 내에서 메타데이터 처리량을 확장할 수 있습니다.
3단계 - 디렉터리 재분산
3단계 디렉터리 재분산은 2단계의 아이디어를 확장하여 자동으로 스트라이프 디렉터리 생성을 지원합니다. 자동 스트라이프 된 디렉터리는 스트라이프 수 1로 시작한 다음 해당 디렉터리의 파일/하위 디렉터리의 수가 증가함에 따라 스트라이프 수를 동적으로 늘립니다. 이렇게 하면 사용자는 디렉터리가 얼마나 커질지 사전에 알지 못하거나 너무 낮거나 너무 높은 디렉터리 스트라이프 수를 선택하는 것에 대해 걱정할 필요 없이 스트라이프 디렉터리를 활용할 수 있습니다.
디렉터리 이관(Directory Migration)
3단계에서는 디렉터리 이관(Directory Migration) 기술이 추가되었습니다. 2단계에서도 마이그레이션은 구현되었지만, 스트라이프 하나의 스트라이프 디렉터리에서 다른 스트라이프 디렉터리로만 마이그레이션이 허용되었습니다. 하지만 3단계에서는 한 스트라이프 디렉터리에서 다른 스트라이프 디렉터리 즉, 스트라이프 수와 상관없이 마이그레이션을 할 수 있도록 기능이 추가되었습니다.
다음은 마이그레이션 하는 명령어 입니다.
[root@Client ~]# lfs migrate -m
ex) 아래 명령어는/testfs/largedir MDT0000에 있는 내용을 MDT0001 및 MDT0003으로 마이그레이션 하는 방법입니다.
[root@Client ~]# lfs migrate -m 1,3 /tetstfs/largedir
QoS 할당(Quality of Service, QoS Allocation)
기존에는 스트라이프 디렉터리 생성할 때 스트라이프의 MDT가 지정되지 않은 경우 디렉터리는 부모가 있는 MDT에 생성되고 첫 번째 스트라이프도 동일한 MDT에 위치하며, 다음 스트라이프는 인덱스 순서대로 다음 MDT에 위치합니다. 이후 MDT 사용량을 재조정하려면 여유 공간과 아이노드가 더 많은 MDT에 스트라이프가 존재해야 하므로 QoS 정책을 통해 스트라이프를 할당합니다.
GPUDirect Storage(GDS) 기술
- GDS 아키텍처
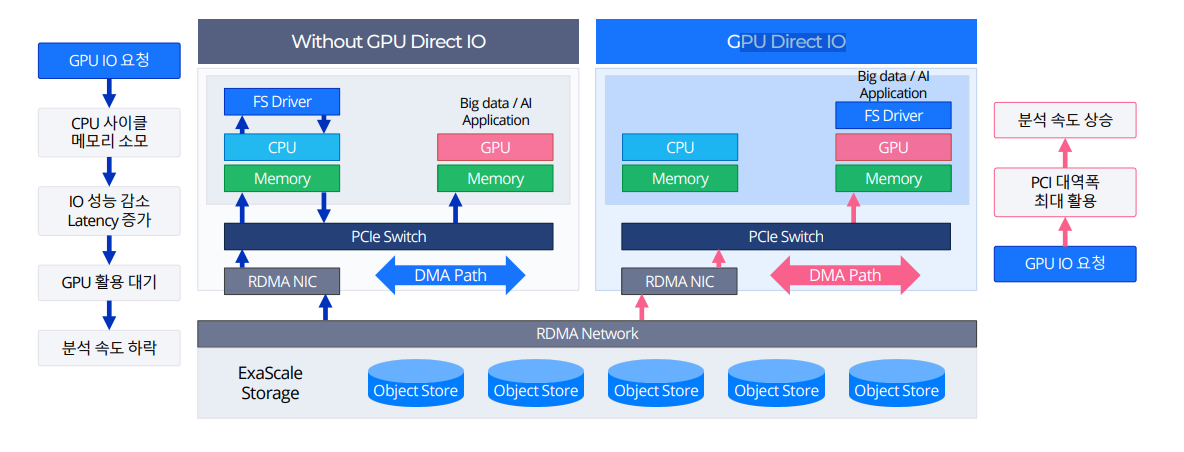
빅데이터, 인공지능, HPC 애플리케이션은 많은 연산을 수행하므로 빠른 연산을 위하여 CPU가 아닌 GPU로 연산을 처리합니다. 하지만 현재 GPU를 사용할 때 입출력이 바로 GPU로 가는 것이 아니라 CPU를 거치고 GPU로 가기 때문에 연산을 처리하는 성능에 있어서 주요 병목 현상이 될 수 있습니다.
NVIDIA는 위와 같은 문제를 해결하고 스토리지와 GPU 메모리간 데이터 이동을 간소화하기 위하여 GDS(GPU Direct Storage)를 만들었습니다.
GDS는 원격 또는 로컬 스토리지와 GPU 메모리 사이에 직접 접근할 수 있는 경로를 생성하는 기술입니다. CPU 메모리의 바운스 버퍼(Bounce Buffer)를 통해 추가 복사본을 만드는 불편한 작업을 하지않습니다. 여기서 바운스 버퍼는 GPU 및 스토리지와 같은 두 장치 간의 데이터 전송을 용이하게 하기위해 시스템 메모리의 임시 버퍼로 정의됩니다. GDS는 이런 과정을 하지않아 CPU에 부담을 주지 않고 GPU로 또는 GPU에서 직접 데이터를 전송할 수 있습니다.
GDS 장/단점
장점
대역폭을 높이고 대기 시간을 줄이며 CPU 및 GPU 처리량 부하를 줄입니다. 또한 스토리지 근처의 Direct Memory Access(DMA)9 엔진이 데이터를 GPU 메모리로 직접 이동할 수 있습니다. 바운스 버퍼를 사용하면 두 가지 복사 작업이 발생합니다.
1. 소스에서 바운스 버퍼로 데이터 복사
2. 바운스 버퍼에서 대상 장치로 다시 복사
직접 데이터 경로에는 원본에서 대상으로 하나의 복사본만 있습니다. CPU가 데이터 이동을 수행할 경우 CPU 가용성에 대한 충돌로 인해 지연 시간이 영향을 받아 불안할 수 있습니다. GDS는 이러한 지연 문제를 완화합니다.
CPU가 데이터를 이동하는 데 사용되는 경우 전체 CPU 사용률이 증가하고 CPU의 나머지 작업을 방해합니다. GDS를 사용하면 CPU의 워크로드가 줄어들고 컴퓨팅 및 메모리 대역폭 병목 현상을 피할 수 있습니다. 가장 명백하게 드라나는 이점은 전송 시간과 대역폭의 약 2배 상승입니다.
단점
GDS는 지원되는 GPU 제품10을 사용해야 하므로 제약적일 수 있고, GPU 에 대한 비용 부담도 클 수 있습니다.
※ GDS 기술을 러스터에서도 이번에 출시된 버전 2.15.0에서 지원한다고 합니다11.
마치며
이번 포스팅에서는 러스터가 무엇인지 어떤 기능을 가지고 있는지와 GPUDirect Storage에 대해 간략하게 알아보았습니다. 다음 시간에서는 러스터 파일시스템을 구성하는 실습과 구성 후 각 기능을 이용한 테스트 및 성능 측정을 해보도록 하겠습니다. 감사합니다~👍
참고
- Introduction to Lustre - Lustre Wiki: https://ko.wikipedia.org/wiki/%EB%9F%AC%EC%8A%A4%ED%84%B0(%ED%8C%8C%EC%9D%BC%EC%8B%9C%EC%8A%A4%ED%85%9C)
- Why use Lustre - Lustre whamcloud Wiki: https://wiki.whamcloud.com/display/PUB/Why+Use+Lustre
- Lustre Wiki Main Page - Lustre Wiki: https://wiki.lustre.org/Main_Page
- What is Lustre - Blog: https://www.weka.io/learn/lustre-file-system-explained/
- Introduction to Lustre & Lustre function - Blog: https://jaynamm.tistory.com/entry/Lustre-File-System
- Introduction to HSM - Git hub: https://github.com/DDNStorage/lustre_manual_markdown/blob/master/03.15-Hierarchical%20Storage%20Management%20(HSM).md
- What is HSM - Blog: https://www.sungardas.com/en-us/blog/what-is-hierarchical-storage-management/
- What is PCC - Lustre whamcloud community: https://jira.whamcloud.com/browse/LU-10092
- Architecture of PCC - DDN storage: https://wiki.lustre.org/images/0/04/LUG2018-Lustre_Persistent_Client_Cache-Xi.pdf
- What is overstripe - whamcloud LUG2019: https://wiki.lustre.org/images/b/b3/LUG2019-Lustre_Overstriping_Shared_Write_Performance-Farrell.pdf
- DoM user guid - Lustre whamcloud community: https://jira.whamcloud.com/browse/LUDOC-385
- Small File I/O Performance in Lustre - Intel: https://wiki.lustre.org/images/c/c5/LUG2018-Small_File_IO_Perf_DataOnMDT-Gmitter.pdf
- Architecture of DNE1 - Lustre whamcloud community: https://wiki.whamcloud.com/display/PUB/DNE+1+Remote+Directories+High+Level+Design
- Introduction to DNE1 - Lustre whamcloud community:https://jira.whamcloud.com/browse/LU-1187?jql=text%20~%20%22DNE%22
- Introduction to GDS - NVIDIA: https://developer.nvidia.com/gpudirect-storage
각주
-
https://wiki.lustre.org/Introduction_to_Lustre ↩
-
https://github.com/DDNStorage/lustre_manual_markdown/blob/master/03.15-Hierarchical%20Storage%20Management%20(HSM).md ↩
-
https://wiki.lustre.org/images/0/04/LUG2018-Lustre_Persistent_Client_Cache-Xi.pdf ↩
-
https://tech.gluesys.com/blog/2021/03/03/NVMe_1.html ↩
-
https://wiki.lustre.org/images/b/b3/LUG2019-Lustre_Overstriping_Shared_Write_Performance-Farrell.pdf ↩
-
https://cug.org/proceedings/cug2019_proceedings/includes/files/pap136s2-file1.pdf ↩
-
https://github.com/DDNStorage/lustre_manual_markdown/blob/master/03.09-Data%20on%20MDT%20(DoM).md ↩
-
https://wiki.whamcloud.com/display/PUB/DNE+1+Remote+Directories+High+Level+Design ↩
-
https://en.wikipedia.org/wiki/Direct_memory_access ↩
-
https://docs.nvidia.com/gpudirect-storage/release-notes/index.html#known-limitations ↩
-
https://wiki.lustre.org/Lustre_2.15.0_Changelog ↩