병렬 네트워크 파일 시스템 pNFS의 재조명
by 박주형 (jhpark@gluesys.com)
AI 서비스의 정확도는 AI 모델의 정교함에 달려 있고, AI 모델의 정교함은 데이터셋을 얼마나 많이 학습했는지에 따라 고도화됩니다. 그리고 학습 시간과 비용을 줄이기 위해서는 데이터셋을 보다 빠르게 처리할 수 있는 컴퓨팅 자원과 데이터를 빠르게 주입해 주는 고성능 스토리지가 필요합니다. 하지만 스토리지는 고성능 컴퓨팅 환경에서 항상 병목의 근원으로 지목되어 왔습니다.
이러한 스토리지 병목 문제를 해결하기 위해 다양한 접근법이 연구되고 있는데, 그중 하나가 기존 NFS(Network File System)의 한계를 극복하고자 등장했던 병렬 NFS(parallel NFS, 이하 pNFS)입니다. 이번 포스트에서는 최근 새롭게 주목받고 있는 pNFS에 대해 소개하겠습니다.
기존 NFS와 병렬 파일 시스템
대부분의 AI 애플리케이션은 리눅스 기반 환경에서 호스팅되며, 보편적으로 리눅스의 기본 스토리지 프로토콜인 NFS를 사용합니다. 하지만 기존 NFS는 클라이언트와 스토리지 사이에 NFS 서버를 통해 데이터를 주고받는 단일 서버 구성입니다. 이 때문에 다수의 클라이언트가 여러 스토리지 노드에 접근하려면 NFS 서버를 통해 접근해야 하고, 1개의 클라이언트가 1개 스토리지 노드에만 접근할 수 있기 때문에 성능이 제한적입니다. 게다가 데이터셋이 커지면 그만큼 대역폭 부하도 높아진다는 문제가 있습니다.
이 때문에 입출력 집약적인 환경에서는 병렬 파일 시스템이 활용됩니다. 병렬 파일 시스템을 통해, 모든 클라이언트는 데이터를 여러 스토리지에 병렬로 직접 요청할 수 있고, 데이터가 여러 스토리지에 분산 저장되어 있기 때문에, 스토리지 노드를 확장할수록 입출력 성능도 높아집니다. 게다가 GPFS와 같은 병렬 파일 시스템의 경우, 메타데이터 서버와 데이터 서버가 분리되어 있어 작업 경로 구분에 따라 대역폭 부하를 크게 줄일 수 있습니다.
하지만 이러한 병렬 파일 시스템은 각 클라이언트에 전용 에이전트를 설치해야 하는 등 설치에 대한 공수와 병렬 인프라에 대한 전문성이 요구되어 유지보수 비용이 발생합니다. 무엇보다, 병렬 파일 시스템이 일반적인 파일 시스템에 비해 상대적으로 기능이 많아 무겁다 보니, 추가 소프트웨어 계층으로 인한 지연 시간과 파일 시스템에 대한 종속성 문제가 있습니다.
pNFS 소개
pNFS는 기존의 단일 NFS 서버의 병목 문제를 해결하기 위해 NFSv4.1부터 등장한 병렬 파일 시스템 구조입니다. 병렬 파일 시스템처럼 데이터와 메타데이터 작업 경로를 구분해 클라이언트가 직접 스토리지에 병렬로 접근할 수 있게 합니다. 데이터와 메타데이터를 구분하여 처리함으로써 기존 NFS의 메타데이터 처리로 인한 네트워크 병목 및 확장성 문제를 해소합니다. 무엇보다, 이러한 병렬 파일 시스템 기능을 리눅스 배포판을 사용하는 모든 환경에서 네이티브로 지원하기 때문에, 추가 하드웨어 및 소프트웨어 계층이 없어도 되고, 별도의 라이선스 비용이 없다는 장점이 있습니다.
pNFS의 구조
pNFS의 아키텍처는 크게 클라이언트와 메타데이터 서버(Metadata Server, 이하 MDS), 데이터 서버(Data Server, 이하 DS)로 구성됩니다. NFS 서버였던 MDS는 메타데이터 및 접근 관리 역할을 수행하며, 레이아웃(layout)이라는 메타데이터에 따라 각 파일의 데이터를 DS에 분산 저장합니다. 레이아웃은 메타데이터 서버에서 관리하며, 파일은 최소 데이터 단위인 유닛(unit)으로 나뉘고 저장 패턴에 따라 DS에 분산 저장됩니다. 파일 접근 시 클라이언트는 pNFS 프로토콜로 MDS에 쿼리를 보내 데이터 위치에 대한 맵과 접근 권한 정보를 얻습니다. 그리고 클라이언트에서 NFS 프로토콜을 통해 각 DS에 저장된 데이터에 직접 접근하고, 레이아웃에 의해 정의된 데이터 유형에 따라 파일, 블록, 오브젝트 프로토콜을 활용할 수 있습니다.
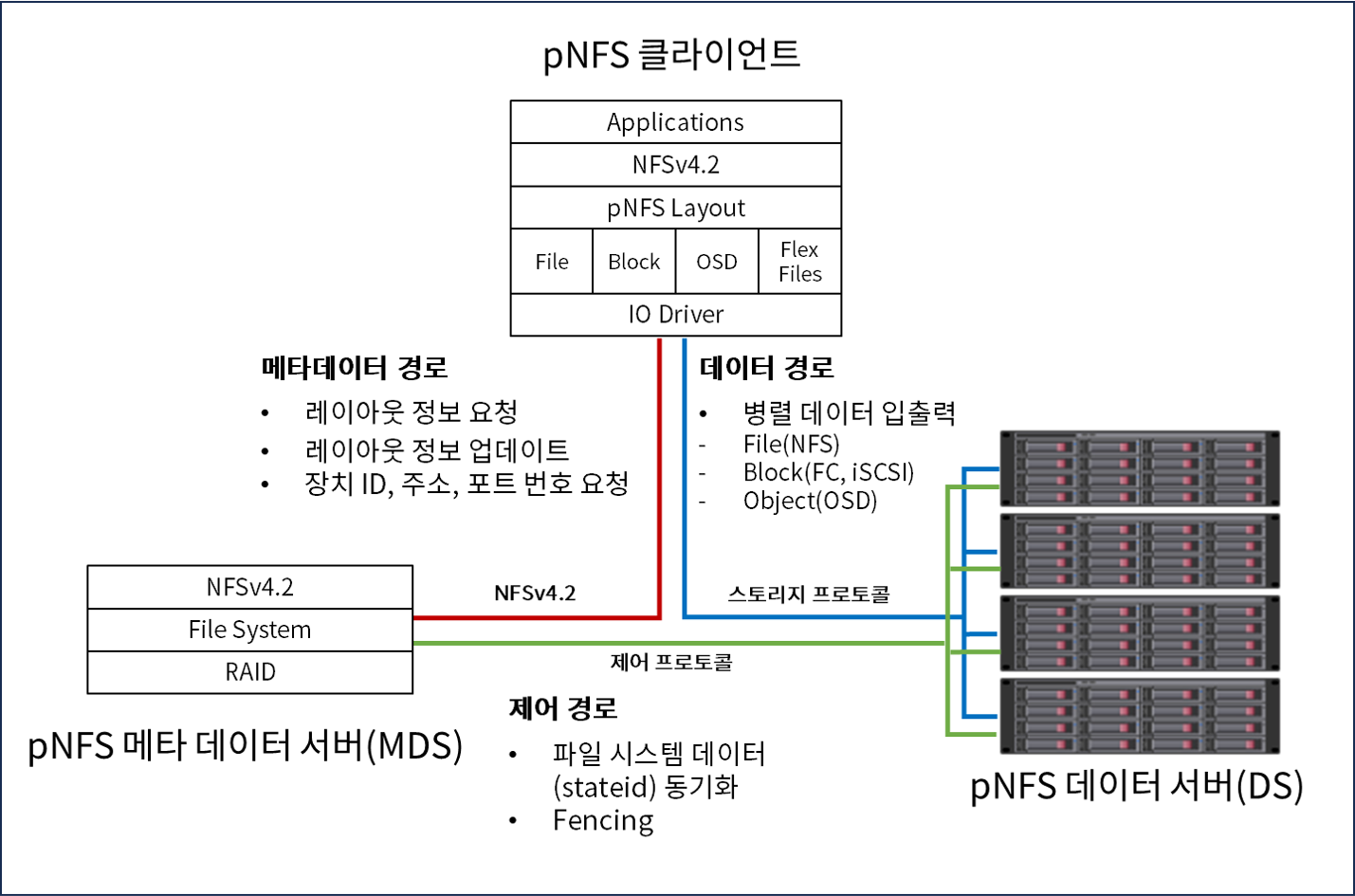
이렇게 NFS 트래픽을 분리하고 클라이언트의 직접 접근까지 가능하게 되었습니다만, 여기에 더해 NFSv4.1부터는 세션 트렁킹(session trunking)을 통해 대역폭을 확장하는 기능까지 추가되었습니다. 세션 트렁킹은 같은 세션 내에 서로 다른 소스와 목적지 주소를 가진 연결을 묶는 것을 말하며, 쉽게 말해 클라이언트와 스토리지 간 인터페이스를 묶어서 대역폭을 확장할 수 있다는 것입니다. 이러한 고대역폭 구성을 통해 클러스터 환경에서 NFS RPC(remote procedure call)를 안정적으로 전송할 수 있게 되었습니다.
Flex Files
NFSv4.2부터는 Flex Files라는 새로운 pNFS 레이아웃이 도입되었습니다. Flex Files(또는 Flexible File Layout)는 파일을 복사하는 도중에도 애플리케이션 서비스의 데이터 접근을 방해하지 않아 데이터 무결성과 서비스 연속성을 보장합니다. 덕분에 데이터 마이그레이션이나 업데이트를 위해 서버를 중단하지 않아도 됩니다. 이러한 데이터 이동은 전적으로 백그라운드에서 동작하기 때문에 클라이언트는 어떠한 유형의 데이터라도 방해 없이 접근할 수 있습니다. 게다가 NFSv3부터 NFSv4.2까지 이전 버전 프로토콜을 통해 DS에 입출력을 요청할 수 있어, 기존 NFSv3를 사용하는 레거시 NFS 스토리지도 클러스터에 추가할 수 있습니다. 또한, 파일 레벨 스트라이핑이 가능해 로드 밸런싱이나 티어링 같은 기능에 최적화되어 있습니다.
Flex Files는 스토리지 장치 수준에서 멀티패스를 지원합니다. 이로써 트렁킹을 통해 대역폭 확장뿐만 아니라 장치 장애 발생에 대비한 고가용성까지 제공할 수 있습니다. 또한, 클라이언트는 멀티패스를 통해 한 데이터 스트라이프 유닛을 불러올 경우, MDS에 추가 레이아웃 요청 없이 한 스토리지 장치 주소에서 다른 장치 주소로 전환할 수 있습니다.
pNFS가 최근 다시 화두가 되고 있는 이유는, 바로 Hammerspace1에서 자사 제품으로 pNFS의 실용성을 증명한 것에 있습니다. Hammerspace는 Flex Files를 리눅스 커뮤니티에 소개해 NFSv4.2에 기여한 바 있으며, AI/ML 워크로드에 최적화된 성능과 확장성을 제공하는 소프트웨어 정의 스토리지 솔루션을 개발했습니다.
고집적 워크로드에 특화된 pNFS
이렇게 pNFS는 기존 목표였던 병렬성뿐만 아니라, 고속 입출력에 대한 요구사항이 보편화되어 가는 현대 스토리지 트렌드에 맞추어 높은 성능과 최적화된 각종 스토리지 기능들을 제공합니다. AI/ML 워크로드는 대규모 데이터셋을 처리하고 분석하는 데 있어 고성능 병렬 파일 시스템을 필요로 하며, pNFS는 이러한 요구사항에 부합할 것으로 보입니다.
- 데이터 경로 최적화로 인한 고성능 입출력: pNFS는 클라이언트가 네임스페이스 내 볼륨에 직접 접근할 수 있으며, 동적인 데이터 배치가 가능해 노드와 스토리지 장치에 유연하게 데이터를 분산시켜 성능과 스토리지 효율성을 높일 수 있습니다. 게다가, MDS와 DS 간 파일 시스템 정보 동기화를 통해 병목을 최소화할 수 있습니다.
- 뛰어난 데이터 접근성: pNFS의 Flex Files 레이아웃은 입출력이 완료되기 전에 신규 레이아웃을 요청할 수 있어, 파일을 복사하는 도중에도 데이터 접근 및 무결성을 유지할 수 있습니다. 게다가, 특정 하드웨어 및 설정에 국한된 일부 병렬 파일 시스템(예: DAOS, GPFS)과는 달리, 어떠한 유형의 스토리지 타입에도 적용할 수 있습니다.
- 클라이언트 중심 메타데이터 관리: 데이터 스토리지의 개입 전에 클라이언트 측에서 메타 데이터에 접근할 수 있어 스토리지의 부하를 줄일 뿐만 아니라, 대규모 메타 데이터의 랜덤 읽기가 많이 요구되는 AI 학습 및 추론에 최고의 성능을 제공할 수 있습니다. 그리고 클라이언트 측에서 레이아웃 정보를 기반으로 데이터의 입출력 수행 경로를 결정할 수 있어 뛰어난 로드 밸런싱 및 서버 병목 해소를 제공합니다.
- 적응형 데이터 운영: 새로운 스토리지 자원이 추가되거나 네트워크 상태가 바뀌는 등 시스템 변화에 맞추어 레이아웃이 동적으로 조정됩니다. 또한, 로드 밸런싱을 위해 클러스터 내 볼륨이 노드 간에 이동해도 파일 시스템 마운트 작업 등 네임스페이스에 개입 없이 위치를 알 수 있어 CPU 및 메모리 집약적인 환경에서도 효율적인 로드 밸런싱이 가능합니다.
마치며
pNFS는 기존 NFS의 한계를 극복하고 NFS가 가진 범용성을 살려 고성능 컴퓨팅 환경에서의 스토리지 병목 문제를 해결하는 혁신적인 기술입니다. 앞으로 pNFS가 AI 및 머신러닝 파이프라인을 위한 스토리지 인프라의 중요한 구성 요소로 자리 잡을 것으로 기대됩니다.
참고
- http://www.pnfs.com/
- https://www.snia.org/educational-library/standards-based-parallel-global-file-systems-and-automated-data-orchestration
- https://www.snia.org/sites/default/files/education/webcasts/What%27s-New-with-NFS-4.2.pdf
- https://www.netapp.com/blog/why-parallel-nfs-is-the-right-choice-for-ai-ml-workloads/
- https://www.keepertech.com/new/wp-content/uploads/2024/05/KT_Hammerspace-pNFS-4.2-File-System-Summary.pdf
- https://www.hpcwire.com/2024/02/29/pnfs-provides-performance-and-new-possibilities/
- https://www.datacenterknowledge.com/data-storage/seven-new-nfs-capabilities
- https://datatracker.ietf.org/doc/html/rfc8435#section-5
각주
-
Hammerspace: pNFS를 기반으로 데이터 오케스트레이션 소프트웨어를 개발한 기업임. Hammerspace의 소프트웨어는 pNFS의 메타데이터 서버에 탑재되어 파일 관리 및 각종 스토리지 기능을 제공함. ↩