스토리지 이중화 2편: NAS 이중화 아키텍처 설계
by 김 태훈 (thkim@gluesys.com)
안녕하세요. 지난번 포스팅 고가용성과 이중화에 이어서 이번 포스트에서는 클라이언트 환경에 따른 스토리지 이중화 아키텍처 설계 방법과 실 구축 사례를 소개하겠습니다.
NAS 이중화 아키텍처
NAS(Network Attached Storage)는 네트워크 기반의 파일 공유 서비스를 수행하는 스토리지이며, 클라이언트는 일반적으로 이더넷 네트워크를 통해 NAS에 접속하여 파일을 저장하거나 불러올 수 있습니다.
이를 위해 NAS는 스토리지 본연의 기능인 볼륨 구성 및 데이터 저장, 백업 등의 기술만이 아닌, 계정 관리와 인증, 파일 공유, 네트워크, 보안 등, 클라이언트 환경에 대한 인프라 기능을 제공해야 합니다.
더 나아가 단일 스토리지가 아닌 NAS 이중화 환경으로 구성할 경우, 이중화를 위한 부수적인 기능들이 추가되어야 합니다. 이때 가장 중요한 요소는 구축하고자 하는 목적과 클라이언트 인프라에 대한 이해입니다. 지난 포스트에서 설명했듯이 잘못된 지점을 모니터링하거나 중요한 지점을 관리하지 못한다면 예상치 못한 장애로 failover가 발생할 수 있습니다.
따라서 NAS 이중화는 스토리지에 대한 기능과 파일 공유를 위한 다양한 요소들을 빠짐없이 모니터링해야하기 때문에 다양한 기술 지식과 환경에 대한 이해를 요구합니다.
도입 사례
그렇다면 실제 구축된 사례를 예시로 NAS 이중화 아키텍처를 설계하는 과정을 설명해보겠습니다.
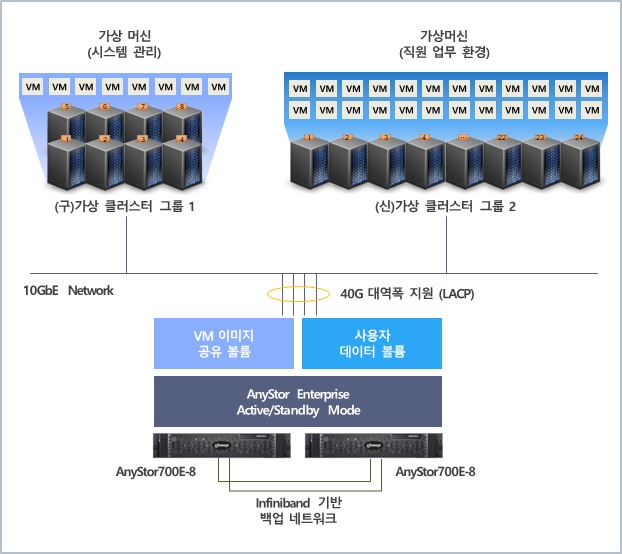
위 그림은 ㅎ사에 구축된 업무 환경을 위한 VDI(Virtual Desktop Infrastructure)1 기반의 시스템 구성도이며, 고객사에서 요구하는 기능은 다음과 같습니다.
ㅎ사의 환경은 조금 특별했습니다. 고객사는 기존에 가상화 기술과 스토리지가 연동된 HCI(Hyper-Converged Infrastructure)5 장비를 통해 가상머신의 이미지를 클러스터 스토리지에서 관리하고, 가상머신으로 NAS를 구축하여 사용자 파일을 공유하고 있었습니다. 하지만 잦은 장애와 부족한 NAS 성능으로 원활한 업무 환경을 제공하기 위해 많은 노력이 필요했다고 합니다.
이번 VDI 구축 사업에는 인프라 구성에 필요한 가상머신 이미지와 개인 사용자 파일을 별도의 고성능 스토리지에 저장하고 공유하기를 원했습니다. 이 경우 NAS에 문제가 발생한다면 사용자 파일 공유뿐만 아니라, 인프라 전체가 다운될 수 있어서 NAS 이중화 환경 구성은 필수였습니다. 만약 장애가 발생하여 standby 스토리지에 서비스가 이전되더라도 실행 중인 가상머신에는 영향이 없어야 하기 때문에 런타임 서비스 이전(runtime failover)이 가능한 고성능 NAS 이중화 기술이 필요했습니다.
가상화 환경을 고려한 스토리지 구성
가상화 환경은 real-time small data 패턴의 입출력 요청(I/O request)이 발생합니다. 저희도 사내 VDI 환경을 구축하여 테스트 용도로 사용하는데, 대부분의 데이터는 4KB 크기를 보이며, 간혹 패키지 등을 다운받을 때 16KB 이상의 데이터도 보이기도 합니다.
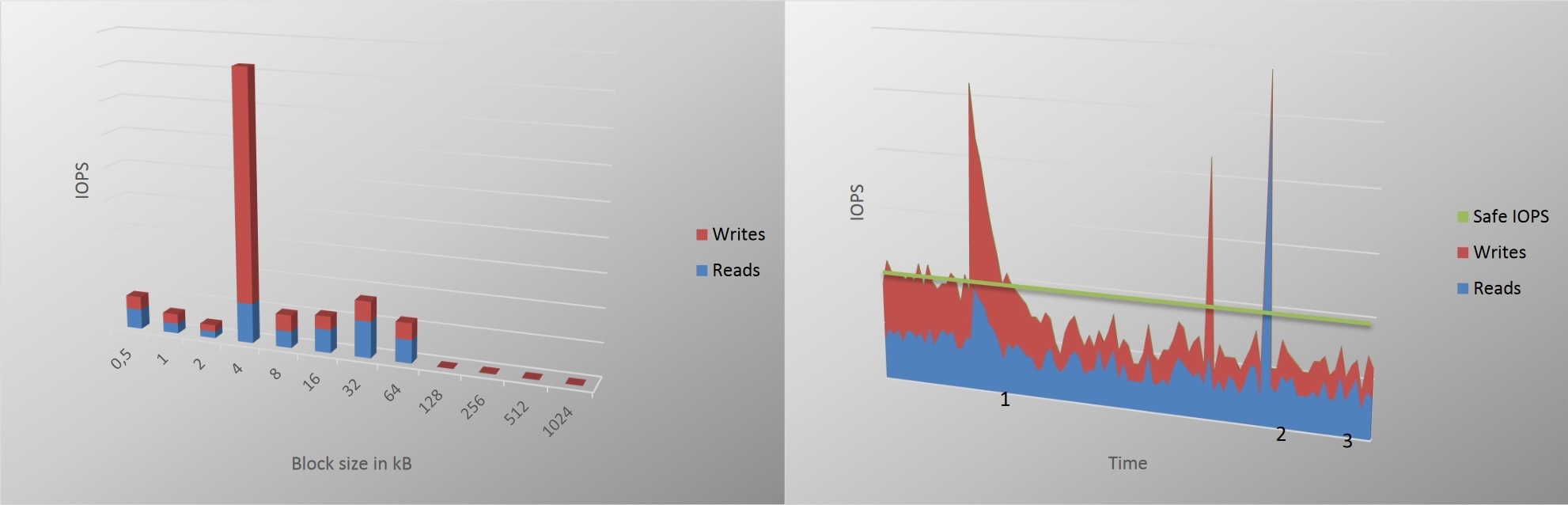
위 그래프는 NetApp의 white paper6에 좋은 내용이 있어서 가져왔습니다. 좌측의 그래프는 VDI 환경의 블록 입출력 패턴을 뜻하며, 대부분의 작업이 4KB 단위로 처리되는 것을 보여줍니다. 우측의 그래프는 평균 IOPS(Input/Ouput Operations Per Second)의 기준을 정하는 방법을 설명합니다. 그래프에서 녹색 가로 라인을 평균 IOPS 기준으로 스토리지 성능을 셋팅했을 때, 1번 포인트에서는 VDI 사용자가 ‘시스템이 느리다.’ 라고 생각할 수 있습니다. 따라서 평균 IOPS를 가장 높은 포인트를 기준으로 설계해야 한다는 내용을 설명합니다.
ㅎ사는 별도의 사용자 데이터가 저장될 공간을 가상머신 이미지로부터 분리했기 때문에 가상머신의 대부분의 입출력 요청은 사용자 파일이 아닌 게스트 운영체제에 의한 것이며, 그 단위는 작게는 수 byte에서 수 KB 정도의 크기입니다. 따라서 ㅎ사의 입출력 패턴에 최적화하기 위해 기존의 파일시스템 기반의 클러스터링 기술이 아닌 블록 기반의 데이터 미러링 기술을 사용했습니다. 클러스터 파일시스템의 공유 단위가 파일이라면, 블록 기반의 데이터 미러링은 실제 디스크에 저장되는 블록 단위로 저장되는 차이점이 있습니다.
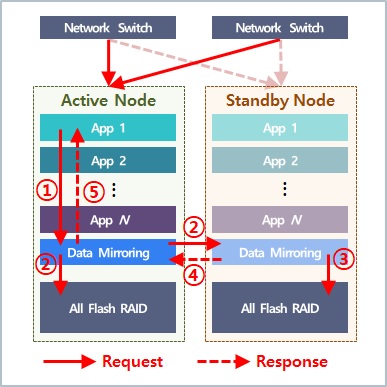
위 그림은 active/active 방식의 NAS 이중화 환경에서 데이터 미러링 기술의 블록 입출력 흐름도 입니다. 클라이언트의 파일 공유 요청은 active 노드에서 처리되며, 파일 요청이 디스크에 전달되고 그 결과를 클라이언트에 응답하는 과정을 설명합니다.
- 클라이언트의 파일 공유 요청은 각각의 서비스 레이어를 지나서 최하단인 데이터 미러링 스택에 전달됨
- Active 노드의 미러링 스택은 블록 입출력 요청을 로컬 디스크와 standby 노드의 미러링 스택에 전달함
- Standby 노드의 미러링 스택은 로컬 디스크에 동일한 블록 입출력 요청을 처리함
- Standby 노드의 디스크에서 처리한 결과를 active 노드에 전달함
- Active 노드의 미러링 스택은 입출력 결과를 상위 서비스에 전달하고 입출력 요청을 완료함
데이터 미러링 기술에서 가장 중요한 이슈는 성능과 안정성입니다. 먼저 이중화된 노드 사이에서 데이터 미러링에 소요되는 지연시간(latency)을 최소화하기 위해 스토리지 간의 통신 인피니밴드(Infiniband)를 사용했습니다. 그리고 약 1000명의 VM과 사용자로부터 발생하는 random access 패턴7에 대한 소요되는 시간을 최소하기 위해 검색 시간(seek time)이 짧은 SSD로 디스크를 구성했습니다. 이때 시스템 내부의 장애 상황을 대비하여 인피니밴드는 본딩(bonding)8 기술을 통해 이중화로 구성했으며, SSD는 RAID-5나 6가 아닌 RAID-10로 구성하여 IOPS를 높이고 패리티 연산으로 소모되는 플래시 메모리 수명을 최소화하여 성능과 안정성을 확보했습니다.
데이터 미러링 기술에는 리눅스에서 블록 기반의 데이터 이중화 기술로 인정받은 DRBD(Distributed Replicated Block Device)9를 사용합니다(DRBD에 대한 설명은 다른 포스트에서 자세히 다루도록 하겠습니다). DRBD에서 노드 간의 통신은 앞서 설명한 바와 같이 인피니밴드를 이용하여 지연시간을 최소화하였으며, 확보된 성능을 활용하여 모든 입출력 요청이 완료된 이후에 완료 응답을 송신하는 DRBD protocol C 타입으로 미러링 했습니다.
또한 클러스터 이중화 기술은 리눅스 분야에서 HA의 표준으로 자리잡은 pacemaker10를 사용합니다. Pacemaker는 Red Hat과 SUSE 등 엔터프라이즈 리눅스를 배포하는 기업의 기술 문서로 제공될 만큼 강력하고 안정성을 인정받은 클러스터 이중화 솔루션 입니다. Pacemaker는 다중 노드에서 active/active와 active/standby 구성을 지원하며 다양한 시스템 모니터링 요소(Resource Agent)를 제공합니다. 또한 필요한 모니터링 기능이 없을 경우 직접 코드를 작성하여 새로운 모니터링 요소를 개발할 수 있습니다.
NAS 이중화 아키텍처 설계
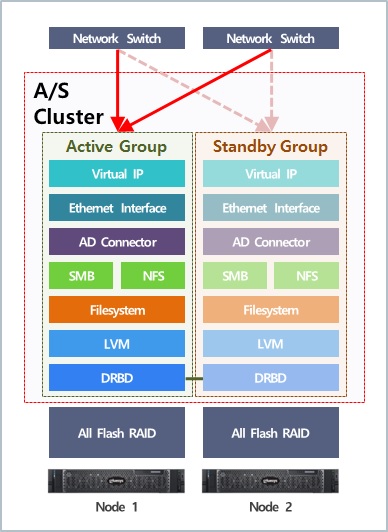
다음으로 고성능 NAS 이중화 구성에 필요한 모니터링 요소와 관계에 대해서 설명하겠습니다. 위 구조도는 ㅎ사에 구축된 NAS 이중화 시스템의 모니터링 아키텍처 입니다. 모니터링 요소 간의 배치는 입출력 요청에 대한 처리 순서와 요소들 간의 관계에 따라서 결정되며, 각 모니터링 요소에 대한 설명은 아래와 같습니다.
- Virtual IP - 클라이언트가 접속하고자 하는 서비스 IP 할당
- Ethernet Interface - Virtual IP가 할당된 네트워크 인터페이스의 상태 확인
- AD Connector - SMB와 NFS에서 사용할 계정 인증 커넥터
- NFS or SMB - 파일 공유 서비스의 상태 확인
- Filesystem - 파일시스템 R/W 가능 여부 확인
- LVM - 볼륨 그룹 및 그룹에 속하는 블록 장치의 상태 확인
- DRBD - 데이터 미러링을 수행하는 클러스터 데몬 상태 확인
네트워크 모니터링 그룹
Virtual IP는 클라이언트가 접속하는 스토리지의 서비스 IP를 나타냅니다. Active/Backup 구성일 때 failover가 발생하면 active 노드에 접속하던 클라이언트의 흐름을 standby 노드로 전환하는 역할을 수행합니다. 또한 어떠한 이유로 IP 설정이 해제될 경우 자동 복구를 수행합니다.
Ethernet Interface는 NIC(Network Interface Controller) 상태를 모니터링합니다. 당시 10Gb 인터페이스 4개를 본딩으로 구성하여 40Gb의 대역폭을 제공했습니다. 다만 기존의 pacemaker에서 제공하던 모니터링 기능은 본딩에 그룹핑된 slave(각각의 10Gb) 인터페이스의 복구 기능을 지원하지 않았습니다. 고객사는 인터페이스에 문제가 생겨 대역폭이 낮아질 경우 엔지니어 개입이 필요 없는 자동 복구 기능을 요청했고, 이에 기존의 모니터링 요소에 복구 기능을 추가 개발하여 제공했습니다.
파일 공유, 인증 모니터링 그룹
AD Connector는 접속하는 사용자의 권한을 확인하기 위해, ㅎ사의 전 직원 계정이 통합된 AD 시스템에 연결하는 기능입니다. 정상 사유로 스토리지의 재시작이 필요하거나, failover가 발생하여 CIFS 서비스가 standby에서 재시작할 경우 수동으로 AD와 재연결을 수행하는데, 이를 자동화하여 엔지니어 개입을 줄여줍니다. AD Connector는 CLI 명령을 자동화해주는 기능을 새로 개발하여 제공한 것으로, 기존의 pacemaker에서는 제공하지 않습니다. (곧 글루시스 깃허브에 공개할게요~ 😘)
NFS, SMB는 파일 공유 서비스를 수행하는 데몬을 모니터링합니다. 시스템 데몬에 문제가 발생할 때 재시작을 지원합니다. systemctl 명령으로 제공하는 리눅스 시스템 데몬들을 모니터링할 수 있습니다.
스토리지 장치 모니터링 그룹
Filesystem은 공유 파일이 저장되는 디스크에 파일이 정상적으로 저장되고 불러오는지 확인합니다. 설정된 주기로 파일시스템 상태를 체크하며, failover가 발생하면 설정한 mount 지점과 filesystem option을 이용하여 자동으로 mount를 수행합니다.
LVM은 리눅스의 LVM(Logical Volume Manager)11으로 생성된 VG(Volume Group)의 상태를 모니터링합니다. VG는 PV(Physical Volume)으로 등록된 블록 장치의 그룹을 뜻하는데, 이때 PV는 DRBD로 매핑된 RAID 볼륨입니다. LVM 모니터링 요소는 지속적으로 블록 장치의 상태를 확인하여 이상 여부를 감지하고 failover 발생 시 설정된 옵션으로 논리 볼륨을 재구성합니다.
마지막으로 DRBD 모니터링 요소는 이중화된 저장소의 클러스터링(연결)과 데이터 동기화 상태를 확인합니다. 이때 두 노드 간의 데이터 동기화 과정에서 스플릿-브레인(Split-Brain)12을 고려해야 합니다. 스플릿-브레인은 클러스터링이 해제되면서 데이터를 양쪽 동시에 사용할 때, 어떤 노드의 데이터가 최신의 데이터인지 확인할 수 없는 장애 상황을 뜻합니다. 클러스터 파일시스템의 경우 글러스터(Gluster)13의 아비터(arbiter) 기능14으로 이를 해결할 수 있지만, DRBD는 엔지니어가 개입하여 장애를 처리해야 합니다. 이러한 상황을 고려하여 스플릿-브레인을 감지하고 복구하는 기능을 추가로 적용했습니다.
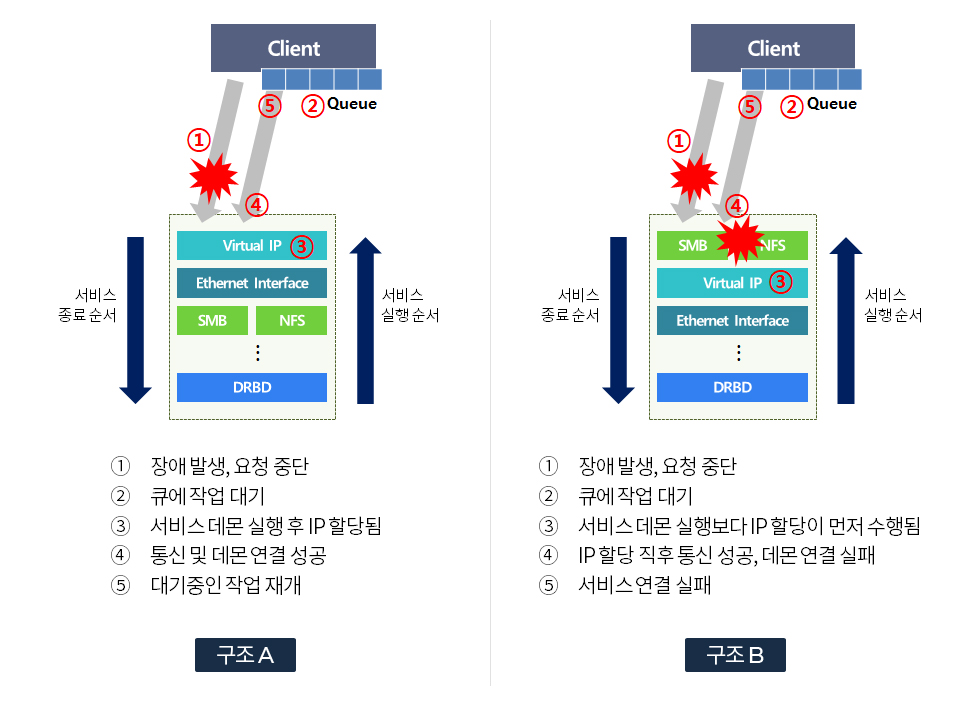
이중화 아키텍처를 설계할 때 주의해야 할 부분은 모니터링 요소의 적절한(정확한) 배치입니다. 한 예로 클라이언트가 접속할 네트워크 주소를 할당하는 Virtual IP 에이전트가 파일 공유 프로토콜 스택인 NFS와 SMB보다 아래에 있다면 failover 발생 시 클라이언트 접속이 끊기게 됩니다. 클라이언트 입장에서 두 구조에 따른 차이는 다음과 같습니다.
- 구조 A (정상)
IP가 할당된 시점에 이미 파일 공유 데몬이 준비되었기 때문에 통신이 재개된 후에 입출력 요청 큐에 대기 중인 작업들도 모두 데몬과 통신하여 처리됨
- 구조 B (비정상)
IP가 할당된 시점에 파일 공유 데몬이 준비되지 않아 통신이 재개된 클라이언트들의 입출력 요청을 처리하지 못함
위 예시처럼 NAS 이중화 아키텍처 설계에서 가장 중요한 부분은 클라이언트 환경에 대한 이해와 기술 간의 관계를 고려하는 것입니다.
마치며
이번 포스트에서는 고객 사례를 예시로 NAS 이중화 아키텍처에 대해서 설명했습니다. 다음 포스트는 미디어 환경에서 active/active 방식의 NAS 이중화 구성 사례를 설명해드리도록 하겠습니다. 또 봐요 ~ 👋
각주
-
https://wikipedia.org/wiki/Desktop_virtualization ↩
-
https://wikipedia.org/wiki/Network_File_System ↩
-
https://wikipedia.org/wiki/Server_Message_Block ↩
-
https://wikipedia.org/wiki/Active_Directory ↩
-
https://wikipedia.org/wiki/Hyper-converged_infrastructure ↩
-
https://www.netapp.com/media/19785-wp-sizing-storage-for-desktop.pdf ↩
-
https://www.infortrend.com/ImageLoader/LoadDoc/509/True/True/Infortrend%20document ↩
-
https://wikipedia.org/wiki/Link_aggregation ↩
-
https://wikipedia.org/wiki/Distributed_Replicated_Block_Device ↩
-
https://wikipedia.org/wiki/Pacemaker_(software) ↩
-
https://wikipedia.org/wiki/Logical_Volume_Manager_(Linux) ↩
-
https://wikipedia.org/wiki/Split-brain_(computing) ↩
-
https://wikipedia.org/wiki/Gluster#GlusterFS ↩
-
https://docs.gluster.org/en/latest/Administrator-Guide/Thin-Arbiter-Volumes/ ↩