Lustre의 파일 create & open 과정 분석 - 1
by 김성환 (shkim3220@gluesys.com)
들어가기 앞서
이번 블로그에서 설명할 내용은 러스터를 활용하고 있는 환경에서 사용자가 새로운 파일을 생성하면, 내부적으로 이루어지는 과정을 분석한 내용을 담고 있습니다.
본 내용은 러스터의 전반적인 구조에 대해 기본적으로 알고 있는 것으로 가정하고 기술하고 있어서, 러스터의 구조가 궁금하신 분들은 Lustre 파일시스템과 GPUDirect Storage 소개[1] 글을 참고하실 수 있습니다.
또한 러스터에서 새로운 파일의 생성은 다양한 컴포넌트들의 상호작용에 의해 이루어지기 때문에, 총 2편에 걸쳐 설명할 예정입니다.
1편에서는 전체적인 흐름을 간략하게 소개하기 위해 러스터의 software stack 및 분석에 활용될 러스터 디버그 시스템에 대한 소개 후, 러스터 클라이언트에서
러스터 서버로 요청을 보내는 부분까지 서술할 예정입니다. 그리고 이어서 2편에서는 러스터 서버에서의 처리 과정과, 서버에서 처리한 내용을 바탕으로 실제
데이터가 쓰일 OST(Object Storage Target)에 접근하는 과정을 서술할 예정입니다.
Lustre software stack
러스터 소프트웨어 스택은 아래 그림과 같이 여러 계층으로 구성되어 있습니다. 해당 그림에서 화살표는 클라이언트에서 러스터 서버로의 요청 흐름을 나타냅니다.
최초 클라이언트에서 실행된 POSIX 시스템 콜은 VFS 계층을 거쳐 러스터의 LLITE(Lustre LITE) 계층으로 이동합니다.
LLITE는 해당 요청이 메타데이터에 대한 접근이 필요한 경우 먼저 LMV(Logical Metadata Volume) 계층으로 요청을 보냅니다. LMV 계층은 단일 MDT(Meta Data Target) 구조일 경우에는
별다른 역할을 수행하지 않지만, 하나 이상의 MDT를 사용하는 구조에서는 사용자의 요청을 분산하는 역할을 수행합니다.
이후 직접적으로 러스터 서버의 MDS(Meta Data Server)와 통신하는 MDC(Metadata Client)로 요청이 보내지고, 최종적으로 MDC가 러스터 서버의 MDS에 요청하게 됩니다.
LLITE에 들어온 요청이 메타데이터가 아니고 데이터에 대한 요청이라면, 해당 요청을 어느 OST로 보낼지 선택하는 LOV(Logical Object Volume) 계층으로 전달됩니다.
LOV는 현재 러스터에 존재하는 클라이언트 수만큼 OSC(Object Storage Client)를 보유하고, 각 OSC를 통해 해당하는 OST에 접근이 가능합니다.
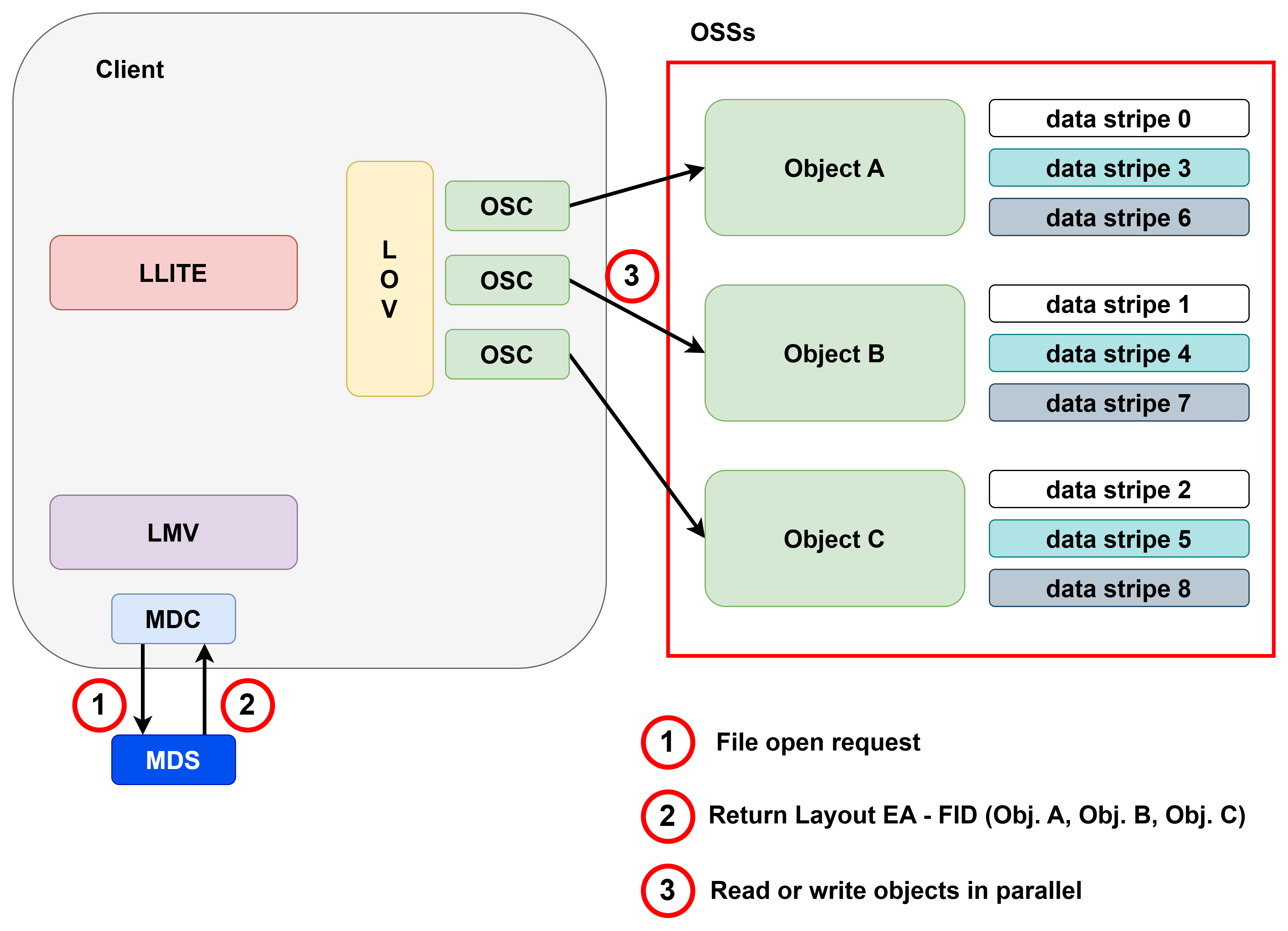
만약 클라이언트에서 파일을 열고 내용을 읽으려고 한다면, 먼저 POSIX를 통해 OPEN 시스템 콜이 호출됩니다.
LLITE는 해당 파일을 열기 위해서는 MDS에 정보를 요청해야 하므로, LMV,MDC를 통해 MDS와 통신해 Layout EA 정보를 받아오게 됩니다.
Layout EA는 Layout Extended Attributes의 약자로, 러스터에서 파일의 레이아웃을 관리하기 위한 자료구조입니다. 이 자료구조는 파일을 식별하기 위한 FID(File Identifiers) 정보와
어느 OST에 존재하는지에 대한 정보가 존재합니다. MDS로 받은 Layout EA를 통해 클라이언트는 LOV,OSC를 거쳐
최종적으로 해당 데이터 블럭이 존재하는 OST에 접근해 데이터를 읽거나 쓰게 됩니다.
다음 내용부터는 러스터에서 새로운 파일을 생성할 때, 위의 software stack에서 어떠한 작업이 이루어지는지를 추적할 방법을 소개한 다음, 클라이언트에서부터 과정을 서술할 예정입니다.
How to lustre debugging
본격적인 내용에 앞서, 해당 내용은 러스터에서 제공하는 디버그 메세지를 바탕으로 작성되었습니다.
실제 러스터를 구축하고, 본문의 내용을 검증하고자 할 때 활용할 수 있도록, 간단히 소개하겠습니다.
debug 설정
러스터에서는 다양한 디버그 메세지들을 분류해 두었기 때문에, 원하는 분류의 메세지만 출력하도록 설정하는 것이 가능합니다.
현재 설정 가능한 분류는 다음과 같습니다.
trace inode super iotrace malloc cache info ioctl neterror net warning buffs other
dentry nettrace page dlmtrace error emerg ha rpctrace vfstrace reada mmap config console quota sec lfsck hsm snapshot layout
설정 방법은 lctl명령어를 활용하여 설정이 가능하며, 다음과 같습니다.
# 단일 분류 설정
lctl set_param debug=+inode
# 복수 분류 설정
lctl set_param debug=+inode,iotrace, ...
# 모든 분류 설정
lctl set_param debug=+all
한 번에 모든 설정들을 제거하고자 할 때는 +all 대신 -all로 설정해 주면 됩니다.
설정이 잘 적용되었는지는 lctl get_param debug로 가능하며, -all로 모든 설정들을 제거하여도
몇 가지 기본적인 설정들을 제외한 나머지가 제거됩니다. 기본 설정 리스트는 다음과 같습니다.
warning error emerg console
subsystem 별 debug 설정
러스터는 메세지뿐만 아니라 subsystem 별로 디버그 메세지의 분류가 가능합니다.
subsystem은 몇 가지를 제외하면 커널 내의 러스터 모듈들을 의미합니다.
따라서 원하는 모듈만 선택적으로 디버깅이 가능합니다. 러스터에서 지원하는 subsystem은 다음과 같습니다.
all_subs, undefined, mdc, mds, osc, ost, class, log, llite, rpc, mgmt, lnet, lnd, pinger, filter, libcfs, echo, ldlm, lov, lquota, osd, lfsck, snapshot, lmv, sec, gss, mgc, mgs, fid, fld
subsystem 설정도 lctl 명령어로 가능하며, 방법은 다음과 같습니다.
# 단일 subsystem 설정
lctl set_param subsystem_debug="mds"
# 복수 subsystem 설정
lctl set_param subsystem_debug="mds mdc ost llite ..."
# 모든 subsystem 설정
lctl set_param subsystem_debug=-1
모든 subsystem을 비활성화하려면 -1 대신 0으로 설정하시면 됩니다.
설정이 잘 되었는지는 lctl get_param subsystem_debug 명령어로 가능하며, 0으로 설정했을 경우 subsystem_debug=0으로 결과가 출력됩니다.
클라이언트의 최초 처리 과정
러스터는 LLITE 계층을 활용해 POSIX로 들어온 요청을 러스터에 맞게 변환해서 활용하고 있습니다.
VFS 계층은 실제 Underlying 파일 시스템에 맞는 Open 함수를 호출하는데, 아래 코드 블럭에서 atomic_open의 dir->i_op->atomic_open 입니다.
// fs/namei.c
/* Handle the last step of open() */
static int do_last(struct nameidata *nd,
struct file *file, const struct open_flags *op,
int *opened)
{
...
error = lookup_open(nd, &path, file, op, got_write, opened);
...
}
static int lookup_open(struct nameidata *nd, struct path *path,
struct file *file,
const struct open_flags *op,
bool got_write, int *opened)
{
....
if (dir_inode->i_op->atomic_open) {
error = atomic_open(nd, dentry, path, file, op, open_flag,
mode, opened);
if (unlikely(error == -ENOENT) && create_error)
error = create_error;
return error;
}
....
}
static int atomic_open(struct nameidata *nd, struct dentry *dentry,
struct path *path, struct file *file,
const struct open_flags *op,
int open_flag, umode_t mode,
int *opened)
{
struct dentry *const DENTRY_NOT_SET = (void *) -1UL;
struct inode *dir = nd->path.dentry->d_inode;
int error;
if (!(~open_flag & (O_EXCL | O_CREAT))) /* both O_EXCL and O_CREAT */
open_flag &= ~O_TRUNC;
if (nd->flags & LOOKUP_DIRECTORY)
open_flag |= O_DIRECTORY;
file->f_path.dentry = DENTRY_NOT_SET;
file->f_path.mnt = nd->path.mnt;
error = dir->i_op->atomic_open(dir, dentry, file,
open_to_namei_flags(open_flag),
mode, opened);
d_lookup_done(dentry);
...
}
이 코드가 수행되면 아래의 코드와 같이 러스터 LLITE 계층의 ll_dir_inode_operations에 정의된 함수인 ll_atomic_open이 호출됩니다.
// lustre/llite/namei.c
const struct inode_operations ll_dir_inode_operations = {
.mknod = ll_mknod,
.atomic_open = ll_atomic_open,
.lookup = ll_lookup_nd,
.create = ll_create_nd,
.mkdir = ll_mkdir,
....
};
Open 과정에서 LLITE의 시작 지점은 ll_atomic_open 함수입니다. ll_atomic_open 함수부터는 inode나 dentry와 같이
일반적인 파일 시스템에 관한 메타데이터 대신 러스터에서 활용하는 메타데이터들로 요청을 처리합니다.
여러 종류의 메타데이터가 존재하지만, 제일 먼저 활용되는 메타데이터는 앞서 언급된 FID 입니다.
FID는 러스터에서 파일이나 디렉토리를 식별하기 위한 메타데이터로, 다음과 같이 정의되어 있습니다.
// lustre/include/uapi/linux/lustre/lustre_user.h
struct lu_fid {
/**
* FID sequence. Sequence is a unit of migration: all files (objects)
* with FIDs from a given sequence are stored on the same server.
* Lustre should support 2^64 objects, so even if each sequence
* has only a single object we can still enumerate 2^64 objects.
**/
__u64 f_seq;
/* FID number within sequence. */
__u32 f_oid;
/**
* FID version, used to distinguish different versions (in the sense
* of snapshots, etc.) of the same file system object. Not currently
* used.
**/
__u32 f_ver;
} __attribute__((packed));
FID의 구성은 sequence 번호(f_seq), object id(f_oid), version(f_ver)으로 구성되어 있습니다.
sequence 번호는 MDS로부터 부여받고, object id는 동일한 sequence 번호에 새로운 파일이 생성되면 순차적으로 증가하며,
version은 버전 관리를 위해 부여되는데 코드 내 주석에서 현재 쓰이지 않는다고 되어있습니다.
아래 디버그 메세지의 fid(0x200000bd2:0x1:0x0)를 예로 들면 f_seq = 0x200000bd2, f_oid = 0x1, f_ver = 0x0이 됩니다.
VFS Op:name=drunk, dir=[0x200000bd2:0x1:0x0](00000000c19f0c4c), file 0000000027a7ccd5, open_flags 8941, mode 81b6 opened 0
이 메세지는 drunk라는 파일을 열고자 할 때, ll_atomic_open 함수에서 기록되는 러스터 디버그 메세지입니다.
0x200000bd2:0x1:0x0 라는 FID를 가진 디렉토리의 하위에서 drunk 라는 파일을 열려고 하고 있습니다. 이때의 FID는
아직 새로운 파일에 대한 FID가 아직 할당되지 않았기 때문에, drunk에 대한 FID는 아직 존재하지 않습니다.
ll_atomic_open 함수가 VFS로부터 요청을 넘겨 받으면 먼저 파일을 단순히 열기만 하는지, 아니면 새로운 파일을 생성하고 여는지 확인합니다.
단순 파일 열기라면 IT_OPEN 플래그만 설정하고, 그게 아니라 파일 생성 후에 여는 작업이라면 O_CREAT 플래그 값까지 설정합니다.
이 후 수행하는 작업은 크게 2가지 입니다. 첫 번째는 ll_lookup_it 이고 두 번째는 ll_create_it 입니다.
ll_lookup_it는 MDS에 해당 파일이 존재하는지 찾고, 없다면 관련 메타데이터 생성까지 요청한 후, ll_create_it 에서 쓸 layout EA 메타데이터를 요청하는 작업까지 수행합니다.
그리고 ll_create_it는 ll_lookup_it의 수행 결과로 받은 layout EA 를 가지고, OST에 실제 파일을 만드는 작업을 수행합니다.
// lustre/llite/namei.c
/*
* For cached negative dentry and new dentry, handle lookup/create/open
* together.
*/
static int ll_atomic_open(struct inode *dir, struct dentry *dentry,
struct file *file, unsigned open_flags,
umode_t mode ll_last_arg)
{
struct lookup_intent *it;
struct dentry *de;
long long lookup_flags = LOOKUP_OPEN;
void *secctx = NULL;
...
it->it_op = IT_OPEN;
if (open_flags & O_CREAT) {
it->it_op |= IT_CREAT;
lookup_flags |= LOOKUP_CREATE;
...
/* Dentry added to dcache tree in ll_lookup_it */
de = ll_lookup_it(dir, dentry, it, &secctx, &secctxlen, &pca, encrypt,
&encctx, &encctxlen);
if (IS_ERR(de))
rc = PTR_ERR(de);
else if (de != NULL)
dentry = de;
CFS_FAIL_TIMEOUT(OBD_FAIL_LLITE_CREATE_FILE_PAUSE, cfs_fail_val);
if (!rc) {
if (it_disposition(it, DISP_OPEN_CREATE)) {
/* Dentry instantiated in ll_create_it. */
rc = ll_create_it(dir, dentry, it, secctx, secctxlen,
encrypt, encctx, encctxlen,
open_flags);
ll_security_release_secctx(secctx, secctxlen);
llcrypt_free_ctx(encctx, encctxlen);
...
out_release:
ll_intent_release(it);
OBD_FREE(it, sizeof(*it));
RETURN(rc);
}
ll_atomic_open의 첫 번째 처리 과정인 ll_lookup_it 함수를 살펴보기 전에, 먼저 함수 이름에 사용된 it에 대해 간단히 설명하고 넘어가도록 하겠습니다.
함수 명의 it는 intent를 의미합니다. 러스터에서는 클라이언트의 요청이 네트워크를 통해 MDS로 전달되어 처리가 되기 때문에,
네트워크 요청을 최소화하기 위해서 한번 요청에 필요한 여러 작업을 전달하려고 이와 같은 방식을 쓰고 있습니다.
다시 ll_lookup_it로 돌아오면, 현재 drunk라는 파일은 새로 생성하려는 파일이므로 아래와 같은 디버그 메세지가 출력 됩니다.
ll_atomic_open 함수에서의 디버그 메세지와 동일하게 생성하려는 파일명, 부모 디렉토리의 FID 가 출력되었고, 수행할 작업(intent)이 추가로 출력되어 있습니다.
VFS Op:name=drunk, dir=[0x200000bd2:0x1:0x0](00000000c19f0c4c), intent=open|creat
이와 같이 MDS에서 수행할 intent가 구성되면, LLITE 계층에서 LMV 계층으로 넘어가게 됩니다.
LMV에서는 먼저 동시성을 위해 MDS에 보낼 Lock에 관한 요청 작업을 처리하는데, 여기에 앞선 파일 열기에 관한 intent를 포함 시킵니다.
이렇게 요청을 만들면, 클라이언트에서 하나의 요청만으로 MDS가 수행이 필요한 모든 작업을 요청할 수 있게 됩니다.
INTENT LOCK 'open|creat' for [0x0:0x0:0x0] 'drunk' on [0x200000bd2:0x1:0x0]
이후 LMV에서는 drunk 파일을 위한 FID를 할당받은 다음 MDS로 요청을 보내기 위해 MDC 계층으로 전달합니다.
cli-cli-ClstAuto-MDT0000-mdc-ffff8e6499843800: Allocated FID [0x200000bd2:0x3fe:0x0]
OPEN_INTENT with fid1=[0x200000bd2:0x1:0x0], fid2=[0x200000bd2:0x3fe:0x0], name='drunk' -> mds #0
최종적으로 위와 같은 요청이 클라이언트의 MDC에서 서버의 MDS로 전달되게 됩니다. 로그에 대해 간단히 설명하면,
ClstAuto는 현재 러스터의 클러스터 볼륨명을 의미합니다. MDT0000 은 클라이언트의 요청이 index가 0인 MDT에 전달되는 것을 의미하고,
mdc는 이 요청은 클라이언트의 mdc가 보냄을 의미합니다.
drunk 파일은 [0x200000bd2:0x3fe:0x0] 이라는 FID를 할당받았고,
MDS 쪽에 이 FID에 관해 요청한 것은 OPEN_INTENT 입니다. fid1은 drunk 파일의 부모 디렉토리의 FID이고, fid2는 drunk 자신의 FID 입니다.
MDC의 요청은 PTLRPC 계층을 거쳐 MDS로 보내지고, 러스터 서버측의 PTLRPC 계층의 데몬이 이를 받아서 MDS 계층에게 넘겨주게 됩니다.
이렇게 create & open 의 시작 부분인 클라이언트의 첫 처리 과정을 코드 레벨로 살펴보았습니다. 이후 MDC의 요청을 받아 MDS에서 처리하는 과정 및 OST 연동 내용은 2편에 이어서 진행하도록 하겠습니다.
참고 링크 및 자료
- [1] Lustre 파일시스템과 GPUDirect Storage 소개
- [2] Lustre Software Release 2.x
- [3] Braam, Peter., “The Lustre storage architecture.”, arXiv preprint arXiv:1903.01955, 2019
- [4] Understanding Lustre Internals, https://wiki.lustre.org/Understanding_Lustre_Internals
- [5] Lustre github