Lustre의 파일 create & open 과정 분석 - 2
by 김성환 (shkim3220@gluesys.com)
들어가기 앞서
이번 블로그에서 설명할 내용은 지난 Lustre의 파일 create & open 과정 분석 -1의 후속 내용으로, 클라이언트에서 보낸 요청이 MDS에서 처리되는 과정과 이후 클라이언트의 후속 처리 과정을 담고 있습니다.
아래 그림에서 1번은 지난 1편 블로그의 내용이고, 2번은 본 편에서 설명할 내용입니다. 1편의 내용을 숙지하고, 2편을 보시면 전체 흐름을 이해하는 데 도움이 될 수 있습니다.
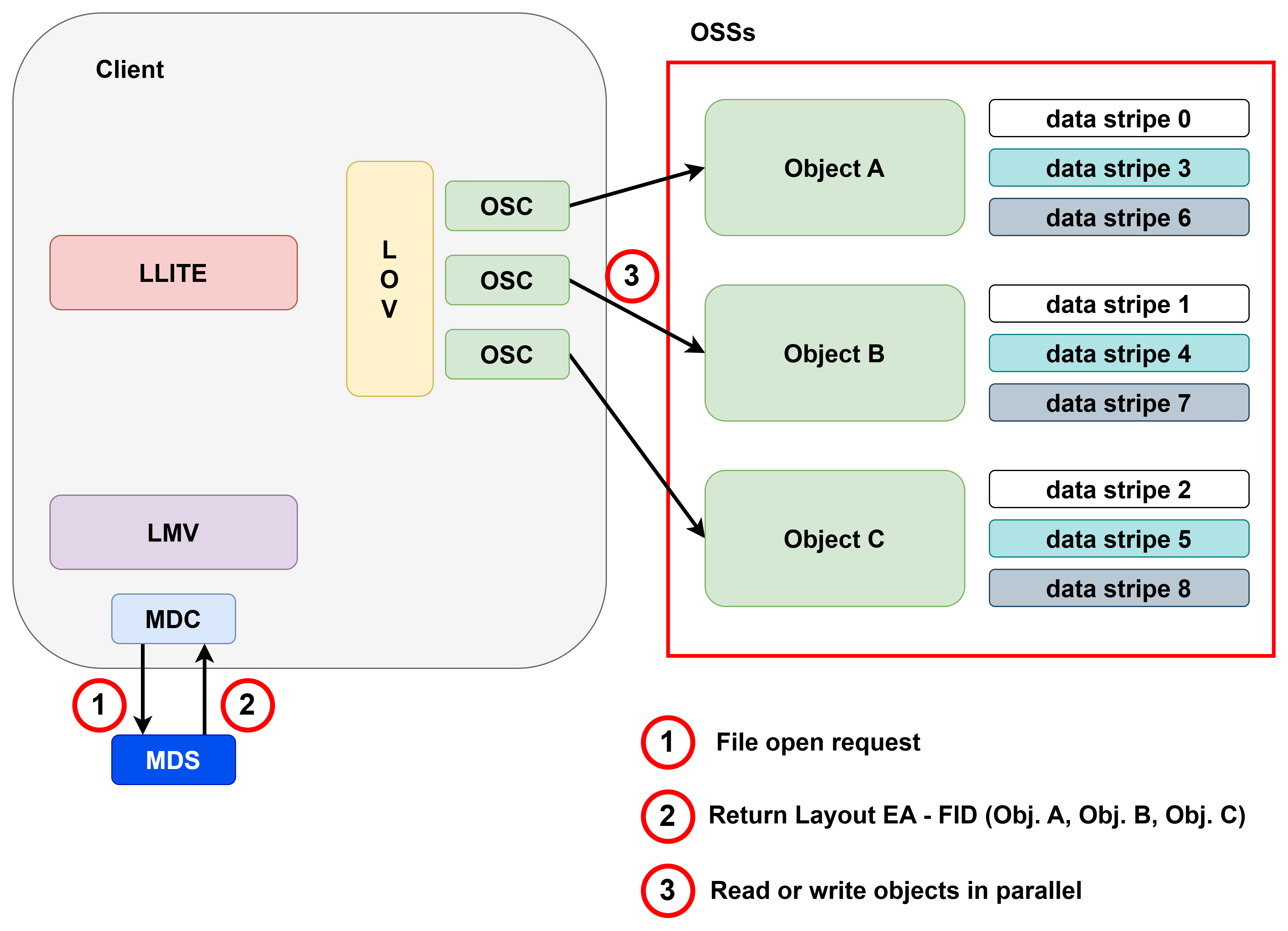
러스터의 전체적인 software stack
MDS에서의 처리
지난 1편에서 클라이언트의 MDC가 보낸 요청을 MDS가 받는 것을 확인하고 마무리 하였습니다.
이 요청을 받아 MDS가 처리하는 과정의 첫 시작은 mdt_reint_open 함수 입니다.
해당 함수는 MDC로 부터 요청을 받으면 다음과 같은 로그 메세지를 출력합니다.
I am going to open [0x200000007:0x1:0x0]/(Melon->[0x20000a811:0x1:0x0]) cr_flag=0100000000102 mode=0100666 msg_flag=0x0
메시지를 살펴보면, 0x20000a811:0x1:0x0 FID를 가진 Melon이라는 파일에 대한 open 요청임을 알 수 있습니다.
그 다음 해당 파일에 대한 lu_object 가 존재하는지 찾는 과정이 mdt_object_find 함수에 의해 수행됩니다.
아래 코드는 mdt_object_find 함수 수행을 포함해 앞으로의 설명에 나오는 함수들 위주로 추린 mdt_reint_open 함수 코드입니다.
// lustre/mdt/mdt_open.c
int mdt_reint_open(struct mdt_thread_info *info, struct mdt_lock_handle *lhc)
{
...
parent = mdt_object_find(info->mti_env, mdt, rr->rr_fid1);
...
fid_zero(child_fid);
result = -ENOENT;
...
if (result == -ENOENT) {
...
child = mdt_object_new(info->mti_env, mdt, child_fid);
} else {
...
if (result == -ENOENT) {
...
result = mdo_create(info->mti_env, mdt_object_child(parent),
&rr->rr_name, mdt_object_child(child),
&info->mti_spec, &info->mti_attr);
if (result == -ERESTART) {
...
out:
if (result)
lustre_msg_set_transno(req->rq_repmsg, 0);
return result;
}
lu_object는 여러 계층으로 구성된 러스터의 디바이스들을 묶어 공통으로 관리하는 객체로 아래와 같은 구조체로 정의되어 있습니다.
// lustre/include/lu_object.h
/**
* Layer in the layered object.
*/
struct lu_object {
/**
* Header for this object.
*/
struct lu_object_header *lo_header;
/**
* Device for this layer.
*/
struct lu_device *lo_dev;
/**
* Operations for this object.
*/
const struct lu_object_operations *lo_ops;
/**
* Linkage into list of all layers.
*/
struct list_head lo_linkage;
/**
* Link to the device, for debugging.
*/
struct lu_ref_link lo_dev_ref;
};
현재 Melon 이라는 파일은 신규로 생성하는 파일이어서 lu_object를 찾지 못하고, 결과값이 -ENOENT로 됩니다(위의 mdt_reint_open 함수 코드에서 result= -ENOENT 부분입니다.)
mdt_reint_open 함수는 결과값이 -ENOENT로 되면, mdt_object_new를 통해 신규로 lu_object 객체를 할당 및 초기화를 진행합니다.
초기화 시에 Melon 파일의 lu_object 계층 구성은 아래와 같이 됩니다.
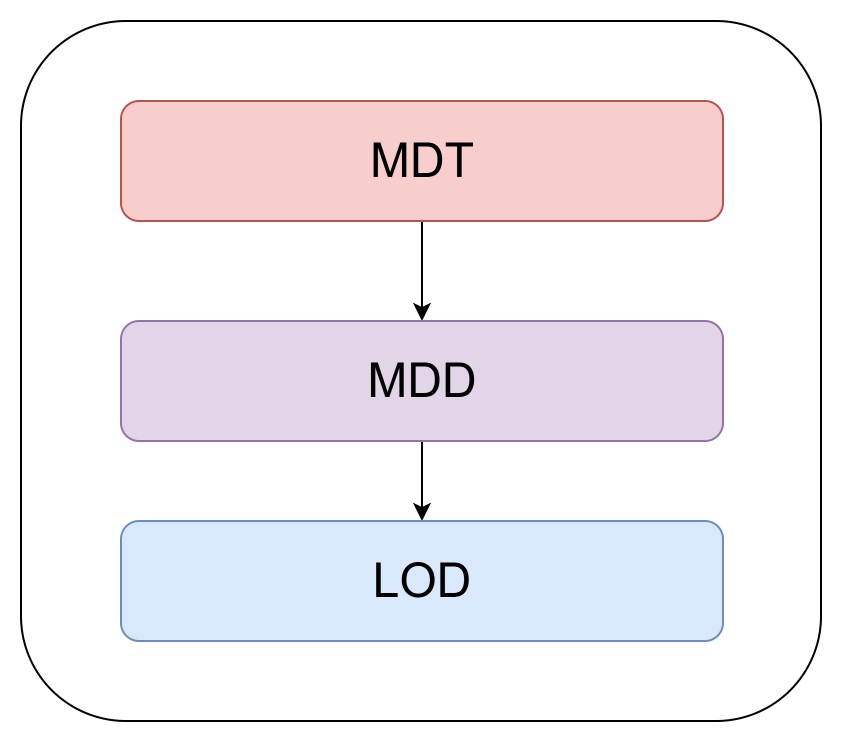
러스터 디바이스 계층 구조
MDD와 LOD라는 새로운 계층이 MDT 하위에 구성되었는데, Lustre 공식 위키의 내용에 따르면 MDD(Metadata Device Driver)는 POSIX appliance 계층으로, 해당 semantics를 구현하기 위해 존재합니다.
그리고 LOD(Logical Object Device)는 러스터에서 쓰는 객체들을 어느 MDT 혹은 OST에 생성할지 결정하는 계층입니다.
위와 같은 계층 구조로 lu_object가 정상적으로 만들어지면, 본격적으로 파일을 생성 및 열기 위한 작업이 수행됩니다.
먼저 mdo_create 함수가 호출되는데, 이 함수는 결과적으로 mdd_create 함수를 호출합니다. mdd_create에서는 크게 다음과 같은 작업을 수행합니다.
- 어느 OST에 해당 파일을 생성 할지에 대한 Hint 생성
- POSIX의 하드 링크 관리를 위한 메타데이터 구성
- 앞선 Hint를 기반으로 파일을 생성할 OST 선택
위 작업과 관련된 함수 내 코드는 아래와 같습니다.
// lustre mdd/mdd_dir.c
int mdd_create(const struct lu_env *env, struct md_object *pobj,
const struct lu_name *lname, struct md_object *child,
struct md_op_spec *spec, struct md_attr *ma)
{
...
mdd_object_make_hint(env, mdd_pobj, son, attr, spec, hint);
...
if (OBD_FAIL_CHECK(OBD_FAIL_LFSCK_BAD_PARENT)) {
struct lu_fid tfid = *mdd_object_fid(mdd_pobj);
tfid.f_oid--;
rc = mdd_linkea_prepare(env, son, NULL, NULL,
&tfid, lname, 1, 0, ldata);
} else {
rc = mdd_linkea_prepare(env, son, NULL, NULL,
mdd_object_fid(mdd_pobj),
lname, 1, 0, ldata);
}
...
rc = mdd_declare_create(env, mdd, mdd_pobj, son, lname, attr,
handle, spec, ldata, &def_acl_buf, &acl_buf,
...
rc = mdd_create_object(env, mdd_pobj, son, attr, spec, &acl_buf,
&def_acl_buf, &hsm_buf, hint, handle, true);
...
}
Hint를 생성하는 작업은 mdd_object_make_hint 함수가 수행하며, 관련된 힌트 정보들은 아래의 dt_allocation_hint 구조체에 저장합니다.
// lustre/include/dt_object.h
/**
* This is a general purpose dt allocation hint.
* It now contains the parent object.
* It can contain any allocation hint in the future.
*/
struct dt_allocation_hint {
struct dt_object *dah_parent;
const void *dah_eadata;
int dah_eadata_len;
int dah_acl_len;
__u32 dah_mode;
int dah_append_stripes;
bool dah_can_block;
char *dah_append_pool;
};
Hint 정보는 해당 파일의 부모 디렉토리의 정보를 바탕으로 구성되며, 부모의 속성 및 striping 정책 등을 활용합니다.
Hint가 구성되고 나면 mdd_linkea_prepare 함수가 호출되어 linkea_data를 구성합니다.
linkea_data는 해당 파일이 어떤 디렉토리 하위에 무슨 이름으로 존재하는지를 담고 있는 구조체입니다.
러스터는 이를 활용해 POSIX의 하드 링크를 손쉽게 관리할 수 있습니다.
// lustre/include/lustre_linkea.h
struct linkea_data {
/**
* Buffer to keep link EA body.
*/
struct lu_buf *ld_buf;
/**
* The matched header, entry and its length in the EA
*/
struct link_ea_header *ld_leh;
struct link_ea_entry *ld_lee;
int ld_reclen;
};
위 두 가지 작업이 끝나면, 본격적으로 OST를 선택하기 위한 과정을 수행합니다.
실질적인 선택은 mdd_declare_create 함수에서 이루어지는데, 일반적인 파일일 경우 lod_qos_prep_create 함수가 최종적으로 호출되게 됩니다. 해당 함수에서 OST를 선택하는 방법은 아래와 같이 구현되어 있습니다.
// lustre/lod/lod_qos.c
int lod_qos_prep_create(const struct lu_env *env, struct lod_object *lo,
struct lu_attr *attr, struct thandle *th,
int comp_idx, __u64 reserve)
{
...
if (lod_comp->llc_ostlist.op_array && // 사용자가 지정한 OST에 할당
lod_comp->llc_ostlist.op_count) {
rc = lod_alloc_ost_list(env, lo, stripe, ost_indices,
th, comp_idx, reserve);
} else if (lod_comp->llc_stripe_offset == LOV_OFFSET_DEFAULT) { // 지정하지 않으면, 먼저 QoS 정책에 의해 할당
/**
* collect OSTs and OSSs used in other mirrors whose
* components cross the ldo_comp_entries[comp_idx]
*/
rc = lod_prepare_avoidance(env, lo);
if (rc)
GOTO(put_ldts, rc);
QOS_DEBUG("collecting conflict osts for comp[%d]\n",
comp_idx);
lod_collect_avoidance(lo, lag, comp_idx);
rc = lod_ost_alloc_qos(env, lo, stripe, ost_indices,
flag, th, comp_idx, reserve);
if (rc == -EAGAIN) // QoS 할당 실패 시 라운드로빈 방식으로 할당
rc = lod_ost_alloc_rr(env, lo, stripe,
ost_indices, flag, th,
comp_idx, reserve);
} else { // 사용자가 지정한 offset에 맞춰 할당
rc = lod_ost_alloc_specific(env, lo, stripe,
ost_indices, flag, th,
comp_idx, reserve);
}
....
먼저 사용자가 지정한 OST들이 있다면, 해당 OST들에 생성되도록 합니다(lod_alloc_ost_list).
만약 별도로 지정하지 않고 기본값을 쓰도록 한다면, 러스터는 자체 QoS 정책에 의해 먼저 OST 선택을 시도하고(lod_ost_alloc_qos),
만약 QoS를 통한 할당이 실패한다면 라운드로빈 방식으로 OST를 선택합니다(lod_ost_alloc_rr).
llc_stripe_offset 값이 기본값이 아니면 사용자가 offset을 지정한 것으로, 이 경우에는 사용자의 요구 사항에 맞춰 선택됩니다(lod_ost_alloc_specific).
offset은 lfs setstripe 명령어에서 -i 옵션을 통해 지정할 수 있습니다.
lfs setstripe -i 3 -c 2 -S 1M <target path, directory or file>
이렇게 선택된 OST에 대한 정보는 추후에 클라이언트가 접근할 때 필요로 하게 되는데, 이를 위해서 러스터는 lovea에 해당 정보를 저장하고 클라이언트에게 넘겨줍니다.
lovea는 별도의 특별한 구조체는 아니고, lu_buf라는 러스터에서 일반적으로 쓰는 버퍼 구조체를 활용합니다.
mdd_declare_create 작업이 완료되면 mdd_create_object를 통해 MDS에 보관이 필요한 메타데이터 객체를 생성하고, 클라이언트에게 응답 메시지를 보냅니다.
이후는 해당 응답 메시지를 활용한 클라이언트 측의 후속 처리 과정에 대한 내용입니다.
클라이언트에서의 후속처리
MDS에서의 작업이 잘 수행되고 응답 메시지를 받으면 클라이언트에서는 ll_create_it 과정이 시작됩니다.
// lustre/lliste/namei.c
static int ll_create_it(struct inode *dir, struct dentry *dentry,
struct lookup_intent *it,
void *secctx, __u32 secctxlen, bool encrypt,
void *encctx, __u32 encctxlen, unsigned int open_flags)
{
...
inode = ll_create_node(dir, it);
if (IS_ERR(inode))
RETURN(PTR_ERR(inode));
...
d_instantiate(dentry, inode);
...
}
ll_create_it에서는 생성하려는 파일에 대해 메타데이터가 정상적으로 만들어졌기 때문에, MDS로부터 받은 lovea의 정보를 lov_stripe_md 구조체에 옮긴 다음, inode에 업데이트합니다.
lov_stripe_md 구조체의 형태는 아래와 같습니다.
// lustre/lov/lov_object.c
struct lov_stripe_md {
atomic_t lsm_refc;
spinlock_t lsm_lock;
pid_t lsm_lock_owner; /* debugging */
union {
/* maximum possible file size, might change as OSTs status
* changes, e.g. disconnected, deactivated
*/
loff_t lsm_maxbytes;
/* size of full foreign LOV */
size_t lsm_foreign_size;
};
struct ost_id lsm_oi;
u32 lsm_magic;
u32 lsm_layout_gen;
u16 lsm_flags;
bool lsm_is_released;
u16 lsm_mirror_count;
u16 lsm_entry_count;
struct lov_stripe_md_entry *lsm_entries[];
};
그리고 최종 적으로 업데이트된 내용을 바탕으로 VFS에게 기존 dentry 경로에 새로운 inode의 추가를 요청합니다.
디버그 메시지 내에서 다음과 같이 저장된 정보를 출력해 주는 것을 확인할 수 있습니다.
lsm 00000000435c78ed, objid 0x1:43025, maxbytes 0x7fffffffffffffff, magic 0x0BD10BD0, refc: 1, entry: 1, mirror: 0, flags: 0,layout_gen 0
[0x0, 0xffffffffffffffff): id: 0, flags: 10, magic 0x0BD10BD0, layout_gen 0, stripe count 1, sstripe size 1048576, pool: []
oinfo:00000000edee2c32: ostid: 0x0:1186 ost idx: 1 gen: 0
해당 디버그 메시지를 통해서 Melon이라는 파일은 1번 OST(ost idx:1)에 객체 ID 값 1186(ostid: 0x0:1186)으로 지정되었음을 알 수 있습니다.
OST 에서의 확인과정
실제 OST에서의 생성은 Write 과정을 통해 이루어지는데, 해당 내용은 이번 분석 범위에 포함되지 않아 생략하도록 하겠습니다.
대신 Write를 통해 정상적으로 쓰였음을 가정하고, 위의 lov_stripe_md에 대한 디버그 메시지 내용대로 잘 생성되었음을 확인하는 과정에 대해 간단히 소개하겠습니다.
그리고 추가로 러스터의 하위 파일 시스템으로 쓰는 ZFS에서도 확인하는 방법을 간단히 소개하고 마치도록 하겠습니다.
먼저 러스터에서는 lfs getstripe 명령어를 통해 다음과 같이 앞선 Melon 파일에 대한 정보 확인이 가능합니다.
lfs getstripe의 결과와 위 디버그 메세지의 결과를 비교해보면, 동일한 것을 확인하실 수 있습니다.
# lfs getstripe Melon
Melon
lmm_stripe_count: 1
lmm_stripe_size: 1048576
lmm_pattern: raid0
lmm_layout_gen: 0
lmm_stripe_offset: 1
obdidx objid objid group
1 1186 0x4a2 0
다음으로 zfs에서 확인하기 위해서는, 우선 현재 1번 OST가 쓰고 있는 zpool 정보를 zpool list를 통해 알 수 있습니다.
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
ost_B 199G 426M 199G - - 0% 0% 1.00x ONLINE -
그다음 출력 내용 중 zpool의 이름을 가지고, zfs에서 제공하는 디버깅 툴인 zdb에 인자로 넘겨주면 정보를 출력할 수 있습니다.
# zdb -e -dddd ost_B
여기서 -e 옵션은 가끔 캐시 정보로 인해 zdb 정보가 정상적으로 출력되지 않는 문제가 발생하는데, 이를 해결하기 위해 캐시를 참조하지 않게끔 하는 옵션입니다.
zdb가 정상적으로 수행되면 ost_B에 대한 정보가 출력되는데, 여기서 앞선 객체 ID 값(1186)에 대한 정보를 찾을 수 있습니다.
Object lvl iblk dblk dsize dnsize lsize %full type
902 2 128K 16K 35K 1K 32K 100.00 ZFS directory
152 bonus System attributes
dnode flags: USED_BYTES USERUSED_ACCOUNTED USEROBJUSED_ACCOUNTED
dnode maxblkid: 1
uid 0
gid 0
atime Thu Jan 1 09:00:00 1970
mtime Thu Jan 1 09:00:00 1970
ctime Thu Jan 1 09:00:00 1970
crtime Wed Jan 22 11:04:17 2025
gen 63
mode 40755
size 0
parent 896
links 0
pflags 800000000000
rdev 0x0000000000000000
Fat ZAP stats:
Pointer table:
1024 elements
zt_blk: 0
zt_numblks: 0
zt_shift: 10
zt_blks_copied: 0
zt_nextblk: 0
ZAP entries: 2
Leaf blocks: 1
Total blocks: 2
zap_block_type: 0x8000000000000001
zap_magic: 0x2f52ab2ab
zap_salt: 0x1859bddd
Leafs with 2^n pointers:
9: 1 *
Blocks with n*5 entries:
0: 1 *
Blocks n/10 full:
1: 1 *
Entries with n chunks:
3: 2 **
Buckets with n entries:
0: 510 ****************************************
1: 2 *
1186 = 338 (type: Regular File)
2 = 964 (type: Regular File)
위 메시지에서 1186은 러스터에서의 객체 ID 값이고, 뒤의 338은 이에 해당하는 zfs에서의 객체 ID 값입니다.
실제로 338에 대한 값을 찾아보면 다음과 같습니다.
Object lvl iblk dblk dsize dnsize lsize %full type
338 1 128K 4K 0 512 4K 0.00 ZFS plain file
312 bonus System attributes
dnode flags: USERUSED_ACCOUNTED USEROBJUSED_ACCOUNTED
dnode maxblkid: 0
uid 0
gid 0
atime Thu Aug 14 15:42:43 2025
mtime Thu Aug 14 15:42:43 2025
ctime Thu Aug 14 15:42:43 2025
crtime Thu Aug 14 15:41:47 2025
gen 2247042
mode 107666
size 0
parent 902
links 1
pflags 800000000000
rdev 0x0000000000000000
SA xattrs: 160 bytes, 2 entries
trusted.lma = \010\000\000\000\000\000\000\000\000\000\001\000\001\000\000\000\242\004\000\000\000\000\000\000
trusted.fid = \021\250\000\000\002\000\000\000\001\000\000\000\000\000\000\000\000\000\020\000\001\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000
간단히 mtime 비교를 위한 ls 명령어 조회 결과는 다음과 같습니다.
# ls -alh
total 200M
drwxr-xr-x 6 root root 25K Aug 14 15:42 .
-rw-r--r-- 1 root root 100M Jan 23 2025 Pumpkin
-rw-r--r-- 1 root root 100M Feb 10 2025 Apple
-rw-r--r-- 1 root root 0 Aug 14 15:42 Melon
mtime 비교는 조금 부족할 수 있어서, 실제 데이터를 가진 다른 파일로 추가 확인을 해보도록 하겠습니다. 현재 Apple 이라는 파일을 열어보면 내부 데이터는 아래와 같습니다.
100M 파일이라, 편의상 일부 데이터만 옮겨 적었습니다.
I have an apple
I have a pen
pineapple
I was a ghost, I was alone, hah
어두워진, hah, 앞길속에 (Ah)
Given the throne, I didn't know how to believe
I was the queen that I'm meant to be
I lived two lives, tried to play both sides
But I couldn't find my own place
Called a problem child 'cause I got too wild
But now that's how I'm getting paid, 끝없이 on stage
이 파일을 먼저 동일하게 lfs getstripe로 확인해보면 다음과 같습니다.
Apple
lmm_stripe_count: 1
lmm_stripe_size: 1048576
lmm_pattern: raid0
lmm_layout_gen: 0
lmm_stripe_offset: 0
obdidx objid objid group
0 1160 0x488 0
현재 0번 OST(obdidx:0)에 존재하고 objid는 1160 인것을 확인 할 수 있습니다. 이를 zdb를 통해 내용을 검색하면 다음과 같이 확인이 가능합니다.
Object lvl iblk dblk dsize dnsize lsize %full type
914 2 128K 16K 35K 1K 32K 100.00 ZFS directory
152 bonus System attributes
dnode flags: USED_BYTES USERUSED_ACCOUNTED USEROBJUSED_ACCOUNTED
dnode maxblkid: 1
path /O/0/d8
uid 0
gid 0
atime Thu Jan 1 09:00:00 1970
mtime Thu Jan 1 09:00:00 1970
ctime Thu Jan 1 09:00:00 1970
crtime Wed Jan 22 11:03:59 2025
gen 61
mode 40755
size 0
parent 896
links 0
pflags 800000000000
rdev 0x0000000000000000
Fat ZAP stats:
Pointer table:
1024 elements
zt_blk: 0
zt_numblks: 0
zt_shift: 10
zt_blks_copied: 0
zt_nextblk: 0
ZAP entries: 2
Leaf blocks: 1
Total blocks: 2
zap_block_type: 0x8000000000000001
zap_magic: 0x2f52ab2ab
zap_salt: 0x16dde0e75
Leafs with 2^n pointers:
9: 1 *
Blocks with n*5 entries:
0: 1 *
Blocks n/10 full:
1: 1 *
Entries with n chunks:
3: 2 **
Buckets with n entries:
0: 510 ****************************************
1: 2 *
8 = 970 (type: Regular File)
1160 = 348 (type: Regular File)
Apple 파일이 부여받은 러스터의 objid 1160은 zfs에서 348의 id값을 가진 object에 존재하는 것을 확인 할 수 있습니다.
이 348 object 의 정보를 동일 zdb 결과 내에서 확인하면 다음과 같습니다.
Object lvl iblk dblk dsize dnsize lsize %full type
348 1 128K 8K 23.5K 512 8K 100.00 ZFS plain file
192 bonus System attributes
dnode flags: USED_BYTES USERUSED_ACCOUNTED USEROBJUSED_ACCOUNTED SPILL_BLKPTR
dnode maxblkid: 0
path /O/0/d8/1160
uid 0
gid 0
atime Thu Jan 1 09:00:00 1970
mtime Mon Aug 11 15:29:09 2025
ctime Mon Aug 11 15:29:09 2025
crtime Mon Aug 11 15:21:58 2025
gen 1725358
mode 100666
size 7902
parent 914
links 1
pflags 800000000000
rdev 0x0000000000000000
SA xattrs: 204 bytes, 3 entries
trusted.lma = \010\000\000\000\000\000\000\000\000\000\000\000\001\000\000\000\210\004\000\000\000\000\000\000
trusted.fid = \101\240\000\000\002\000\000\000\015\000\000\000\000\000\000\000\000\000\020\000\001\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000
trusted.version = \074\000\000\000\025\000\000\000
Spill block: 0:21003a8000:2000 200L/200P F=1 B=1725487/1725487 cksum=0000000463402dff:000001c2ded1efcc:00005d31e8e4d796:000d328f2dec511d
Indirect blocks:
0 L0 0:2100040000:4000 2000L/2000P F=1 B=1725487/1725487 cksum=000002da23a8c5b2:000bf16a4d8e66fa:2022a6b4b0f36087:9e7ec08e337a8708
segment [0000000000000000, 0000000000002000) size 8K
이 object 정보를 활용해서 zfs 혹은 러스터에서 실제 데이터 확인이 가능한데, 러스터에서 추적하는 방법만 소개하도록 하겠습니다.
위 정보에서 path 정보가 /O/0/d8/1160 으로 나와있는 것을 확인 할 수 있습니다. 이를 OST 가 마운트된 경로에서 해당 파일을 열어보면 되는데,
기본적으로 러스터는 readonly로 마운트 되기 때문에 열어 볼 수 없습니다. 해서 zfs 스냅샷 기능을 활용해 스냅샷을 찍고 복제본을 만들어 마운트하면 확인이 가능합니다.
최종적으로 복제본이 마운트된 경로에 해당 파일을 열어보면 다음과 같이 확인이 가능합니다.
> # pwd
> /ost/ost_debug/O/0/d8
> # ls
> 1160 8
> cat 1160
I have an apple
I have a pen
pineapple
I was a ghost, I was alone, hah
어두워진, hah, 앞길속에 (Ah)
Given the throne, I didn't know how to believe
I was the queen that I'm meant to be
I lived two lives, tried to play both sides
But I couldn't find my own place
Called a problem child 'cause I got too wild
But now that's how I'm getting paid, 끝없이 on stage
마치며
지금까지 러스터의 디버그 메시지를 바탕으로, 러스터에서 하나의 파일을 생성하고 열 때의 과정을 소개하였습니다. 러스터는 다양한 컴포넌트들이 분산 환경에서 동작하기 때문에 분석 과정에 많은 어려움이 있는데, 소개한 내용이 도움이 되셨길 바라며 마치도록 하겠습니다.
참고 링크 및 자료
- [1] Lustre의 파일 create & open 과정 분석 -1
- [2] Lustre Software Release 2.x
- [3] Braam, Peter., “The Lustre storage architecture.”, arXiv preprint arXiv:1903.01955, 2019
- [4] Understanding Lustre Internals, https://wiki.lustre.org/Understanding_Lustre_Internals
- [5] Lustre github