ZFS 파일 시스템
by 박주형 (jhpark@gluesys.com)
이번 기술 블로그 포스트에서는 ZFS에 대해 소개하고자 합니다.
ZFS 소개
ZFS는 잘 알려진 파일 시스템 중에서도 비교적 최근에 등장한 파일 시스템입니다. 2001년 썬 마이크로시스템즈에서 자사 운영체제인 솔라리스의 일부로 개발을 시작했습니다. ZFS는 안정성과 성능, 그리고 데이터 보호 기능들이 강화된 파일 스토리지를 목적으로 개발되었습니다. 이후 오픈소스로 공개했었으나, 2010년에 오라클이 썬 마이크로시스템즈를 인수한 이후로는 오라클 ZFS라는 명칭으로 사유화되었습니다. 이와는 독립적으로 2013년부터 오픈소스 프로젝트인 OpenZFS가 오픈소스의 명맥을 이어 나가고 있습니다.
일반적으로 64비트나 그 이하를 지원하는 파일 시스템들과는 달리, ZFS는 128비트 파일 시스템입니다. 이론상 단일 스토리지 풀의 최대 지원 용량이 256,000조 제타바이트로, 사실상 실제 환경에서 보기 어려운 용량 제한을 가지고 있습니다. 현재(2023년 12월) 기준으로 존재하는 파일 시스템 중 가장 큰 비트 사이즈를 지원한다고 볼 수 있습니다. 또한, ZFS의 기본 블록 크기는 128KB이지만 가변 블록 크기를 지원해 필요에 따라 블록 크기를 변경할 수 있습니다. 워크로드마다 최적의 블록 크기가 다르기도 하고, 압축 기능 사용 시 작은 블록 크기를 활용해 압축 효율을 높일 수도 있습니다.
ZFS의 핵심 컨셉은 바로 파일 시스템과 볼륨 매니저를 같이 제공한다는 것입니다. 기존의 파일 시스템은 스토리지 장치별로 볼륨을 생성하고, 이 볼륨들을 관리하기 위해 볼륨 매니저가 필요했습니다. 대표적으로, ext4나 XFS와 같은 파일 시스템은 LVM(Logical Volume Manager) 과 같은 볼륨 매니저를 통해 다수의 물리적인 스토리지를 관리하고 별도의 하드웨어 및 소프트웨어 RAID 와 연계해 데이터 보호 기능을 제공해 왔습니다. 하지만 ZFS는 이러한 기능들을 한 번에 제공하는 것이 특징입니다. 물리적인 스토리지와 이로 구성된 볼륨 구조뿐만 아니라, 여기에 저장된 파일에 대한 정보도 가지고 있습니다. 이 때문에 물리적인 디스크를 추가할 때 중단 없이 스토리지 풀에 추가할 수 있고, 해당 풀을 사용하는 파일 시스템들이 즉시 신규 스토리지 공간을 활용할 수 있게 합니다.
ZFS의 주요 기능
ARC 및 L2ARC 캐싱
ZFS는 빠른 입출력을 지원하기 위해 독자적인 캐싱 메커니즘을 제공합니다. 다만, 모든 캐시를 RAM에 저장하기에는 공간과 비용 문제가 있어 SSD와 같은 고속 스토리지 미디어에 분산시키는 계층형 캐시 구조를 채용했습니다.
-
ARC(Adaptive Replacement Cache)는 메모리에 저장되는 캐시입니다. ARC에 저장되는 데이터는 접근 시간이나 빈도뿐만 아니라, 캐시와 디스크 중 읽은 데이터의 출처가 어디가 더 많은지(hit ratio, 캐시 적중률)도 확인해서 캐시 적중률이 높은 데이터를 중심으로 저장합니다. 이는 결국 캐시 적중률이 낮은 데이터에 대한 접근도 빨라질 수 있습니다. 캐시 적중률이 높은 데이터를 저장할수록 디스크 접근에 대한 부하도 낮아지기 때문에, 결국 디스크에 저장된 캐시 적중률이 낮은 데이터에도 빠르게 접근할 수 있기 때문입니다.
-
L2ARC(Level 2 ARC)는 ARC의 보조 저장 공간을 위해 SSD를 활용한 캐시입니다. ARC에서 데이터를 찾지 못하였다면 디스크에 접근하기 전 L2ARC에서 빠르게 찾아볼 수 있어 데이터에 대한 높은 접근성을 제공합니다. 일반적으로 RAM보다는 느리지만, vdev를 구성하는 스토리지 미디어보다는 빠른 SSD를 사용합니다.
체크섬
ZFS가 가진 또 하나의 특징은 바로 데이터 무결성을 최대한 보장하도록 디자인되었다는 것입니다. ZFS는 파일 시스템의 모든 계층의 모든 데이터와 메타데이터에 대한 체크섬을 제공합니다. ZFS의 스크럽(Scrub) 기능을 통해 체크섬 계산으로 데이터의 손상 여부를 확인하는 유효성 검사를 수행하고, 필요시 복구하는 자가 복구(Self-healing) 과정을 통해 bit rot와 같은 사일런트 커럽션까지 대처할 수 있습니다. 그리고 이 모든 과정을 메모리에서 수행하기 때문에 실시간 작업이 가능합니다. 데이터 블록의 체크섬 데이터는 같이 저장되지 않고, 해당 데이터 블록의 포인터와 함께 저장됩니다. 이 때문에 파일 시스템이 감지할 수 없는 데이터 블록 손상이 발생하는 이슈에 영향이 없다고 볼 수 있습니다.
Copy-on-Write
ZFS는 기본적으로 COW(copy-on-write) 메커니즘을 활용해 데이터를 저장합니다. 쓰기를 수행할 때 기존 데이터에 단순히 덮어쓰지 않고, 스토리지의 다른 영역에 새로운 데이터만 쓰고 메타데이터를 업데이트하는 방식을 말합니다. 이로써 시스템 장애 발생 시, 최근에 쓰기를 수행한 데이터는 잃을 수도 있겠지만, 기존 데이터나 파일 시스템에 대한 영향은 방지할 수 있어 데이터 자산 손실을 최소화할 수 있습니다.
스냅샷 및 클론
ZFS가 기본적으로 COW 방식으로 데이터를 저장하고 있기 때문에 스냅샷을 생성하는 것이 매우 수월하다고 볼 수 있습니다. 단순히 특정 시점에 파일 시스템이 기록한 포인터의 복제를 만들어 놓는 것으로 즉각적으로 스냅샷을 만들 수 있습니다. 이렇게 특정 시점별로 생성된 스냅샷으로 랜섬웨어나 시스템 장애 등이 발생 시 손실된 데이터를 복구할 수 있습니다.
이런 스냅샷은 기본적으로 읽기 전용이지만, 쓰기 가능한 스냅샷(또는 클론)도 생성할 수 있습니다. 클론은 두 개의 독립적인 파일 시스템이 특정 데이터 블록을 공유하는 형태입니다. 클론 중 한쪽에 새로운 데이터 쓰기가 발생하면 새로운 데이터 블록에 대한 쓰기가 수행되지만, 기존 데이터는 어느 클론이든 동일한 상태로 유지합니다.
압축 및 중복 제거
ZFS는 인라인 데이터 압축과 중복 제거 기능을 제공합니다. ZFS는 LZ4, GZIP, LZJB, ZLE 등 다양한 압축 알고리즘을 지원하고, 중복된 데이터를 체크섬으로 찾아 제거하는 중복 제거 기능을 통해 데이터 저장의 효율을 높입니다. ZFS 압축 및 중복 제거 기능은 메모리를 많이 소모하기 때문에 기본적으로 비활성화되어 있습니다.
RAIDZ
ZFS는 RAIDZ라는 자체적인 소프트웨어 RAID 기능을 제공합니다. 제공하는 RAID 수준은 RAIDZ-1, RAIDZ-2, RAIDZ-3로 구분되며, 뒤에 붙는 숫자는 각각 RAID 수준에서 지원하는 패리티의 개수를 말합니다. 한마디로 각각 RAID 5, RAID 6, 3개 패리티를 지원하는 RAID로 보시면 됩니다. 다만 RAIDZ는 기존 RAID와는 다른 점이 몇 가지 있습니다. RAIDZ는 COW를 활용하기 때문에 메타데이터로 높은 수준의 데이터 무결성을 제공하고, 메타데이터에 대한 이중화 및 체크섬을 제공합니다. 또한, 기존 RAID와는 달리 블록 크기가 스트라이프마다 다른 크기로 저장될 수 있고, 모든 스트라이프를 새로 쓰기 때문에 RAID 5의 쓰기 구멍(write hole) 이슈1에서 자유롭다고 볼 수 있습니다.
ZFS의 스토리지 풀 구조
ZFS의 스토리지 풀은 크게 여러 디스크를 포함한 가상 장치인 vdev(virtual device의 약자)와 스토리지 풀을 말하는 zpool(ZFS pool의 약자), 그리고 데이터셋으로 구분됩니다.
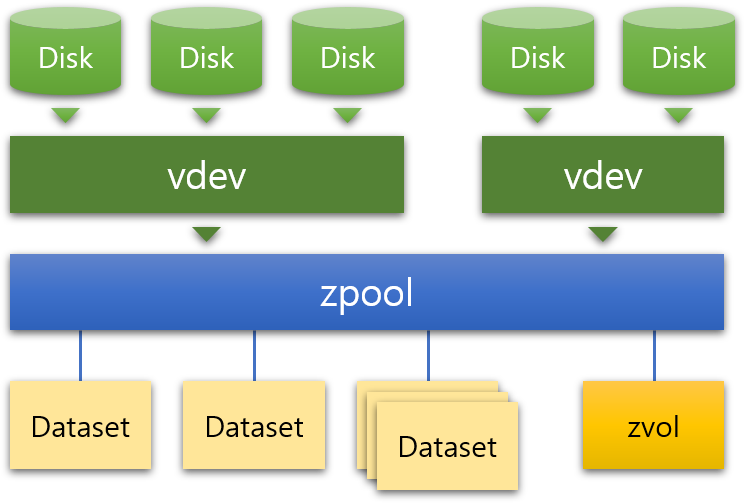
vdev
먼저 vdev는 스토리지 풀을 구성하는 최소 단위로, 하나 이상의 디스크나 RAID 그룹 등으로 구성됩니다. 데이터 vdev는 일반적인 데이터 저장을 목적으로 한 vdev이며, 앞서 설명한 RAIDZ 구성뿐만 아니라 디스크 간 미러링 및 스트라이핑 구성으로도 설정할 수 있습니다. 대부분의 vdev는 이처럼 일반적인 스토리지 용도로 쓰이지만, 캐시, 로그, 스페어와 같은 용도로도 쓰입니다.
-
캐시(cache): 캐시 vdev는 L2ARC 캐시를 위한 공간을 말하며, 읽기 전용으로 제공됩니다. 주로 데이터 vdev 보다 높은 성능의 SSD로 구성합니다.
-
스페어(spare): 데이터 vdev에서 문제가 발생한 디스크를 자동으로 대체하기 위해 확보한 vdev입니다. 핫 스페어라고도 합니다.
-
로그(log): 로그 vdev는 SLOG(Separate Intent Log)라고도 불리며, 쓰기 전용 캐시입니다. 설정 시, 데이터 vdev에 데이터를 쓰기 전에 우선적으로 저장되며, 전력 장애 등 발생 시 데이터를 SLOG에서 읽어와 쓰기가 수행되지 못한 데이터를 복구할 수 있습니다. 캐시 vdev와 마찬가지로 높은 성능의 SSD로 구성합니다.
zpool
zpool은 ZFS 구조에서 최상위 계층에 있는 스토리지 풀로, 기본적으로 하나 이상의 vdev로 구성됩니다. 하나의 서버에는 여러 zpool이 존재할 수 있으며, 각 zpool은 독립적이라 서로 vdev를 공유할 수는 없습니다. zpool은 vdev를 추가함으로써 확장이 가능하지만, 역으로 풀을 줄이는 것은 불가능합니다. 이처럼 zpool은 vdev의 구성에 따라 용량을 유연하게 관리할 수 있으며, 이는 모두 ZFS 파일 시스템이 볼륨 구조뿐만 아니라 파일에 대한 모든 정보를 관리하기 때문입니다.
이로 인한 장점 중 하나로, 결함이 발생한 디스크 교체 시 복구가 빠르다는 점이 있습니다. 디스크 장애가 발생할 경우, 결함이 발생한 디스크를 교체하고 새로운 디스크에 기존 데이터를 저장하는 리실버링(resilvering) 과정을 거칩니다. 일반적인 RAID 환경에서는 데이터를 전부 검사하는 과정이 필요하지만, ZFS 파일 시스템은 zpool의 모든 데이터를 파악하고 있기 때문에 필요한 부분만 리실버링을 수행해 작업 시간을 단축할 수 있습니다.
데이터셋
데이터셋은 zpool의 스토리지 풀을 공유하는 일종의 볼륨 또는 파티션이라고 볼 수 있습니다. 데이터셋은 zpool 내 여러 개의 파일 디렉터리처럼 생성될 수 있으며, 데이터셋 아래에 데이터셋이 존재할 수도 있습니다. 또한 데이터셋 마다 크기는 물론, 스냅샷, 쿼터, 압축 및 중복 제거 등 다른 설정으로 생성할 수 있다는 점도 특징입니다.
추가로, 데이터셋 말고도 zvol이라는 볼륨도 있습니다. zvol은 데이터셋과 같이 zpool을 사용하지만, 데이터셋처럼 파일 시스템 구조가 아닌 기본적인 블록 레벨로 데이터를 관리합니다. 이 때문에 다른 파일 시스템을 올리거나 iSCSI 익스포트 등의 용도로 활용할 수 있습니다.
ZFS 도입 시 고려해야 할 점
이처럼 ZFS는 NAS에서 널리 사용되는 파일 시스템 중에서도 다양한 기능과 안정성으로 널리 사용되고 있지만 실제로 도입하는 데 있어서 몇 가지 확인이 필요한 부분들이 있습니다. 예를 들어, ARC를 제대로 활용하기 위해서는 일정 수준 이상의 메모리 자원이 요구됩니다. 이 때문에 캐싱 등 메모리 자원이 많이 필요한 환경에서는 그만큼 메모리 용량을 늘릴 필요가 있겠습니다. 게다가 파일 시스템이 단일 서버 환경으로 제한되어 있기 때문에, 스케일아웃 스토리지 환경을 구성하려면 Lustre나 GPFS와 같은 병렬 파일 시스템과 연계하는 방법을 찾아야 합니다. 무엇보다 ZFS는 현재 오픈소스인 OpenZFS와 상용인 Oracle ZFS로 양분되어 있다는 점도 고려해야 합니다. OpenZFS는 직접 구축해야 하는 수고가 있지만 무료로 받을 수 있고 OpenZFS를 탑재한 상용 제품이 여럿 있어 선택지가 있고, Oracle ZFS는 Oracle 스토리지 제품에 종속되어 있고 비용이 발생하지만, Oracle의 기술지원 서비스를 받을 수 있다는 장점이 있습니다.
마치며
이번 포스트에서는 ZFS의 개요와 주요 기능 및 구조를 소개하고, 도입 시 고려해야 할 부분들을 간단하게 다루어 보았습니다. 앞으로도 ZFS와 같은 파일 시스템을 소개하는 포스트를 조금씩 올려보고자 합니다.
참고
- https://itslinuxfoss.com/zfs-vs-xfs-file-system/
- https://www.programmathically.com/xfs-vs-zfs-which-file-system-is-best-for-your-use-case/
- https://hetmanrecovery.com/recovery_news/why-is-the-zfs-file-system-in-linux-ubuntu-so-good.htm#plan_14
- https://openzfs.org/wiki/System_Administration
- https://itsfoss.com/what-is-zfs/
- https://computingforgeeks.com/raid-vs-lvm-vs-zfs-comparison/
- https://en.wikipedia.org/wiki/ZFS
- https://www.open-e.com/blog/pooled-storage/
- https://www.techtarget.com/searchstorage/definition/ZFS
주석
-
RAID 5 쓰기 구멍이란, 쓰기 작업 중에 전력 장애 등으로 패리티가 제대로 쓰이지 않은 경우, 이를 감지 못한 채 놔두는 상황을 말합니다. 만일 이 상태로 RAID 리빌드 작업을 수행하게 된다면 데이터 손실이 발생하게 됩니다. ↩