Lustre Changelog DR
by 김 재환 (jhkim@gluesys.com)
목차
인사말
2022년 10월 15일 발생한 SK C&C 데이터센터 화재와 2025년 9월 26일 국가정보자원관리원 데이터센터 화재 사례에서 보듯이, 예기치 못한 재난 상황에서도 시스템이 정상적으로 운영되기 위해서는 데이터 손실을 최소화할 수 있는 효율적인 백업 및 복구 전략이 필수적입니다.
데이터센터에서의 재해 복구(Disaster Recovery) 계획에서 RPO(Recovery Point Objective)1는 가장 중요한 지표 중 하나로, RPO가 짧을수록 재난 발생 시 보호할 수 있는 데이터의 범위가 넓어져 비즈니스 연속성을 보다 안정적으로 보장할 수 있습니다.
하지만 Lustre와 같은 대용량 분산 파일시스템 환경에서는 전체 데이터를 주기적으로 동기화하는 기존 방식이 많은 시간과 자원을 요구한다는 한계가 있습니다. 이러한 제약을 극복하기 위해 변경된 데이터만을 추적하고 동기화하는 방식을 적용하면, 동기화 시간을 크게 줄이고 RPO를 최소화할 수 있습니다.
이번 블로그에서는 Lustre 파일시스템에서 파일 생성, 수정, 삭제와 같은 모든 메타데이터 변경 이벤트를 기록하는 Changelog2 기능과, 이를 기반으로 구현한 글루시스의 DR 솔루션을 소개합니다.
이전에 제가 작성한 블로그 Lustre_FID_1과 Lustre_FID_2에서 Lustre의 파일 생성 방식과 파일의 고유한 FID(File Identifier)로 관리하는 방식에 대해 다루었습니다. 해당 내용은 이번 블로그에서 설명하는 Changelog와 DR 솔루션의 동작 원리를 이해하는 데 도움이 되니 참고해 주시기 바랍니다.
전통적인 rsync 방식의 한계와 파일 히스토리 기반 DR
DR을 구현하기 위해 전통적으로 사용되는 방식은 rsync3를 활용한 전체 스캔 기반 동기화입니다. 이 방식은 SSH 명령어 또는 SSH 데몬을 통해 실행할 수 있으며, 파일시스템 전체를 주기적으로 스캔하여 변경된 파일을 식별한 뒤 이를 동기화합니다.
그러나 rsync 기반 동기화 방식은 파일시스템 전체를 스캔한 이후에야 동기화가 이루어지기 때문에, 파일시스템의 규모가 커질수록 스캔 시간이 선형적으로 증가하는 한계를 가집니다. 특히 Lustre와 같은 대규모 파일시스템에서는 동기화에 수십 시간이 소요될 수 있으며, 동기화 주기가 스캔 주기에 의존하게 되어 RPO를 최소화하는 데에도 제약이 발생합니다. 이러한 이유로, 대규모 파일시스템 환경에서 실시간에 가까운 DR을 구현하기에는 전통적인 rsync 방식만으로는 한계가 있습니다.
이러한 한계를 극복하기 위한 대안으로, 파일 히스토리를 기반으로 한 DR 방식을 고려할 수 있습니다. 해당 방식은 파일시스템에서 발생한 변경 이력을 기반으로 수정된 파일 목록만 선별하여 동기화함으로써, 전체 파일시스템을 반복적으로 스캔하는 rsync 방식에 비해 스캔에 소요되는 시간을 크게 줄일 수 있습니다. 더 나아가 파일시스템 모니터링을 통해 변경된 파일 정보를 실시간에 가깝게 수집할 수 있다면, RPO를 최소화하는 고효율 DR 환경을 구현할 수 있습니다.
Lustre Changelog
Lustre Changelog는 Lustre 파일시스템에서 발생하는 모든 메타데이터 변경 사항을 기록하는 기능입니다.
파일 생성, 수정, 삭제, 권한 변경, 디렉토리 구조 변경 등과 같은 이벤트들이 시간 순서대로 기록되며, 이를 통해 파일시스템의 변경 이력을 추적할 수 있습니다.
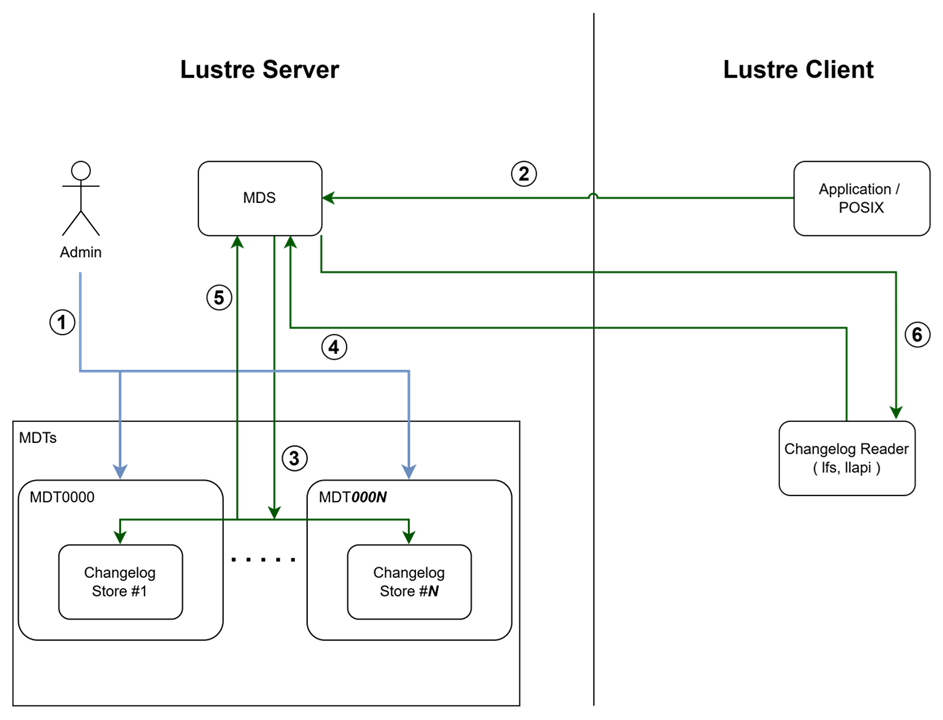
Changelog 동작 흐름:
-
Changelog 등록: Lustre 관리자가
changelog_register로 MDT(Metadata Target)에 Changelog를 등록합니다. 이 과정을 통해 해당 MDT에서 발생하는 메타데이터 변경 이벤트를 기록할 수 있습니다. -
클라이언트 I/O 발생: 클라이언트가 파일 생성, 수정, 삭제 등의 I/O 작업을 Lustre 파일시스템에 요청합니다.
-
Changelog 저장: MDS(Metadata Server)가 클라이언트의 I/O 작업을 확인하고 처리한 후, 해당 이벤트를 Changelog로 MDT에 저장합니다. 각 이벤트는 타임스탬프, FID, 이벤트 타입 등의 정보와 함께 순차적으로 기록됩니다.
-
Changelog 읽기 요청: Changelog Reader(
lfs changelog명령어 또는llapi_changelog_recv()API)가 Changelog 내용을 확인하기 위해 읽기 요청을 보냅니다. -
Changelog 조회: MDS가 MDT에서 Changelog를 가져와 읽기 요청에 대응할 데이터를 준비합니다.
-
Changelog 전달: MDS가 조회한 Changelog 내용을 Changelog Reader에게 전달합니다. Reader는 이 정보를 활용하여 파일시스템 변경 이벤트를 실시간으로 추적하고 처리할 수 있습니다.
Changelog의 동작 원리
Changelog는 MDS에서 관리되며, 각 MDT별로 독립적으로 기록됩니다.
클라이언트에서 메타데이터 변경 작업이 발생하면, MDS는 해당 작업을 처리한 후 Changelog에 이벤트를 기록합니다.
Changelog는 내부적으로 순차적인 로그 파일 형태로 저장되며, 각 로그 엔트리는 다음과 같은 정보를 포함합니다:
- 타임스탬프: 이벤트 발생 시간
- FID: 변경된 파일 또는 디렉토리의 FID
- 이벤트 타입: CREAT, UNLINK, RENME, SETATTR 등의 작업 유형
- 부가 정보: 작업과 관련된 추가 메타데이터
Changelog는 비동기적으로 기록되기 때문에 일반적인 파일시스템 작업 성능에는 거의 영향을 주지 않습니다. 다만, 활성화된 이벤트 타입이 많을수록 디스크 사용량이 증가할 수 있으므로, 실제로 필요한 이벤트만 선택적으로 활성화하는 것이 좋습니다.
Changelog 활성화 및 확인
Changelog 기능을 사용하려면 먼저 MDS에서 Changelog를 활성화해야 합니다.
Changelog는 기본적으로 비활성화되어 있으며, 다음과 같이 활성화할 수 있습니다:
# 1. Changelog 등록 (changelog_register)
lctl changelog_register <MDT_device>
# 2. Changelog 활성화 및 이벤트 타입 설정
lctl set_param mdd.*.changelog_mask="CREAT UNLINK RENME SETATTR"
# 3. Changelog 상태 확인
lctl get_param mdd.*.changelog_mask
먼저 changelog_register를 통해 MDT에 Changelog를 등록한 후, changelog_mask 파라미터를 통해 기록할 이벤트 타입을 선택적으로 지정할 수 있습니다. 필요한 이벤트만 기록하도록 설정하면 디스크 사용량을 절약할 수 있습니다.
changelog_mask 이벤트 타입
changelog_mask에서 사용할 수 있는 주요 이벤트 타입은 다음과 같습니다:
파일 및 디렉토리 작업:
- CREAT: 파일 또는 디렉토리 생성
- UNLINK: 파일 또는 디렉토리 삭제
- MKDIR: 디렉토리 생성
- RMDIR: 디렉토리 삭제
- RENME: 파일 또는 디렉토리 이름 변경
파일 속성 및 메타데이터:
- SETATTR: 파일 속성 변경 (권한, 소유자, 그룹 등)
- SATTR: 파일 속성 설정 (SETATTR과 유사하지만 세부 동작이 다름)
- XATTR: 확장 속성(Extended Attribute) 설정 또는 변경
- TRUNCATE: 파일 크기 변경
파일 접근:
- OPEN: 파일 열기
- CLOSE: 파일 닫기
HSM 관련:
- HSM: HSM(Hierarchical Storage Management) 관련 작업 (파일 아카이빙, 복원 등)
기타:
- MARK: 마커 이벤트 (특정 시점을 표시하기 위한 이벤트)
- ATIME: 접근 시간 변경 (기본적으로 비활성화)
- GXATR: 확장 속성 접근 (기본적으로 비활성화)
- NOPEN: 파일 열기 거부 (기본적으로 비활성화)
일부 이벤트 타입(ATIME, GXATR, NOPEN 등)은 기본적으로 비활성화되어 있으며, 이러한 이벤트를 기록하려면 명시적으로 mask에 포함시켜야 합니다.
다만, 이러한 이벤트는 빈번하게 발생할 수 있어 디스크 사용량이 크게 증가할 수 있으므로 신중하게 선택해야 합니다.
Changelog 읽기
Changelog를 읽기 위해서는 lfs changelog 명령어를 사용합니다:
# 특정 MDT의 Changelog 읽기
lfs changelog <MDT_device>
# 특정 시점 이후의 Changelog 읽기
lfs changelog <MDT_device> <start_record>
# 실시간으로 Changelog 모니터링
lfs changelog <MDT_device> --follow
Changelog는 순차적인 레코드 번호를 가지며, 특정 레코드 번호부터 읽어올 수 있습니다. 각 레코드는 다음과 같은 형식으로 출력됩니다:
12345 08/01/2025 14:30:25 CREAT [0x200000007:0x1:0x0] /lustre/test/file.txt
12346 08/01/2025 14:30:26 MODIFY [0x200000007:0x1:0x1] /lustre/test/file.txt
12347 08/01/2025 14:30:27 UNLINK [0x200000007:0x1:0x1] /lustre/test/file.txt
각 레코드는 레코드 번호, 타임스탬프, 이벤트 타입, FID, 그리고 파일 경로(가능한 경우)를 포함합니다. 이 정보를 활용하여 특정 시점 이후의 변경 사항만 추출하거나, 특정 파일의 변경 이력을 추적할 수 있습니다.
글루시스 DR 솔루션
지금까지 Lustre의 Changelog 기능에 대해 소개해 보았는데요, 글루시스에서도 Lustre의 Changelog 기능을 적용한 DR 솔루션을 제공하고 있습니다.
글루시스 DR 솔루션은 실시간으로 파일시스템 내 변경 사항을 추적해 원격 사이트에 동기화하는 기능을 제공합니다.
rsync와 같은 전통적인 동기화 방식과 달리, 변경된 파일만 효율적으로 추적하고 복제하기 때문에 네트워크 트래픽과 처리 시간을 크게 절감할 수 있습니다.
주요 특징
효율적인 증분 동기화
전체 파일시스템을 스캔하는 대신, Changelog를 통해 변경된 파일만 식별하여 동기화합니다. 이를 통해 대규모 파일시스템에서도 빠른 동기화가 가능하며, 네트워크 트래픽을 효율적으로 활용할 수 있습니다.
실시간 동기화
이벤트 발생 즉시 처리되므로, 재해 발생 시 최신 데이터까지 복구할 수 있습니다. 또한 Changelog Index를 추적하여 시스템 재시작 후에도 중복 처리나 누락 없이 동기화를 계속할 수 있습니다.
안정적인 오류 처리
동기화 실패 시 상세한 오류 정보를 기록하고, 재시도 가능한 작업은 자동으로 재시도 큐에 추가하여 처리합니다. 실패한 파일 목록을 추적하여 관리자가 수동으로 처리할 수 있도록 지원합니다.
파일 필터링 시스템
설정 파일의 excludePatterns를 통해 불필요한 파일, 확장자를 동기화 대상에서 제외할 수 있습니다. 기본적으로 Vim 임시 파일(.swp, .swo, .swx)과 백업 파일(~)이 제외됩니다.
시스템 구성
글루시스 DR 솔루션은 다음과 같은 기술 스택으로 구성됩니다
-
모니터링
실시간성이 중요한 모니터링 작업을 위해, 해당 컴포넌트는 C 언어로 구현되어 Lustre API를 직접 호출하여 이벤트를 수집합니다.
이는lfs changelog와 같은 사용자 레벨 도구를 통해 간접적으로 Changelog를 조회하는 방식보다, 호출-응답 지연을 최소화하고 불필요한 프로세스 오버헤드를 줄일 수 있어 성능과 리소스 효율 측면에서 유리하기 때문입니다. -
이벤트 큐
Redis Stream4을 사용하여 이벤트를 비동기적으로 전달합니다. -
원격 통신
gRPC5를 사용하여 타겟 서버와 통신합니다.
gRPC는 google이 개발한 HTTP/2 기반의 고성능 RPC(Remote Procedure Call) 프레임워크로, 타입 안전성과 효율적인 직렬화를 제공합니다. -
파일 동기화
SSH 기반 rsync를 사용하여 안전하고 효율적으로 파일을 전송합니다.
rsync는 증분 동기화에 최적화된 도구로, 변경된 부분만 전송하여 네트워크 대역폭을 절약합니다. SSH를 통해 암호화된 안전한 전송을 보장합니다. -
설정 관리
가독성이 좋고 다양한 프로그래밍 언어에서 쉽게 파싱할 수 있는 JSON 파일로 관리합니다.
시스템 아키텍처
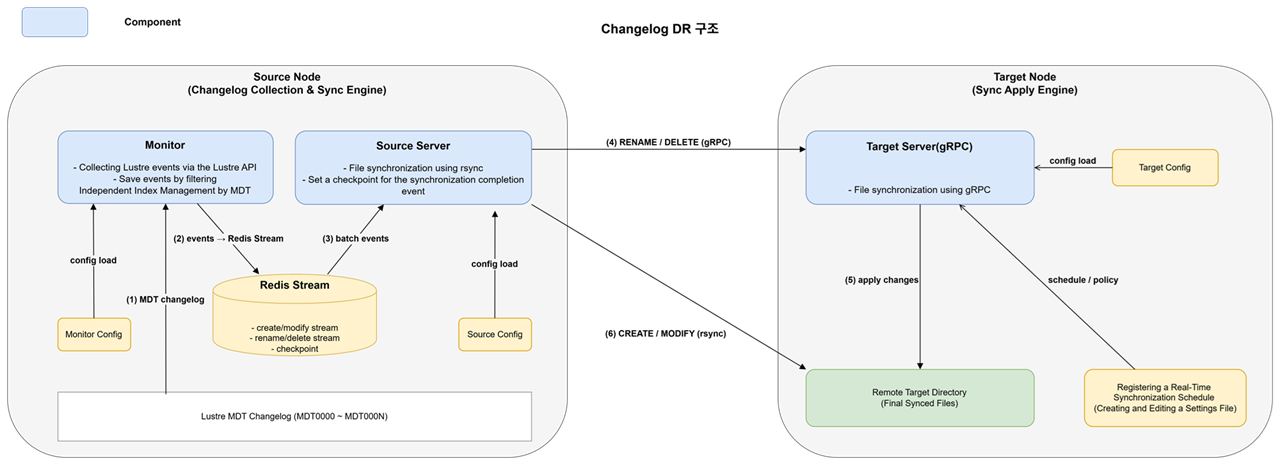
글루시스 DR 솔루션은 세 가지 주요 컴포넌트로 구성됩니다:
-
모니터링 컴포넌트
Lustre Changelog를 실시간으로 모니터링하고 이벤트를 수집합니다. -
소스 서버 컴포넌트
소스 서버에서 실행되며, 수집된 이벤트를 처리하고 동기화 작업을 수행합니다. -
타겟 서버 컴포넌트
타겟 서버에서 실행되며, 원격에서 전송된 파일 작업 요청을 처리합니다.
이 세 컴포넌트는 Redis Stream을 통해 이벤트를 전달하고, gRPC를 통해 원격 파일 작업을 수행합니다.
컴포넌트별 상세 기능
모니터링 컴포넌트
- MDT가 여러 개인 경우, 각 MDT별로 독립적인 프로세스로 동작합니다.
- 메인 스레드 1개와 서브 스레드 2개로 이루어진 멀티 스레드 구조입니다.
- 메인 스레드: MDT 상태를 모니터링하고 코드 내 리소스를 관리합니다.
- 모니터링 스레드: Lustre Changelog 이벤트를 수집합니다.
- 필터 스레드: 설정 파일에 정의된 필터링을 이용하여 Redis에 저장합니다.
- Lustre Changelog 이벤트는 원본, create_modify, rename_delete 세 그룹으로 분류하여 저장합니다.
소스 서버 컴포넌트
- Redis Stream에서 이벤트를 가져와 처리합니다.
- rsync를 통한 동기화 작업은 create_modify 그룹을 가져옵니다.
- gRPC를 통한 동기화 작업은 rename_delete 그룹을 가져옵니다.
- MDT별 Changelog Index와 동기화 체크포인트를 관리합니다.
타겟 서버 컴포넌트
- rename_delete 그룹에 속한 파일 목록에 있는 파일을 동기화합니다.
동작 원리
1. 이벤트 수집 단계
모니터링 컴포넌트는 Lustre의 llapi_changelog_recv() API를 사용하여 파일시스템 변경 이벤트를 실시간으로 수집합니다.
각 MDT(Metadata Target)별로 독립적인 프로세스로 동작하며, 수집된 이벤트는 Redis Stream에 저장됩니다.
이 과정에서 불필요한 파일(예: Vim 임시 파일, 백업 파일 등)은 설정 파일의 excludePatterns를 통해 필터링되어 동기화 대상에서 제외됩니다.
또한 시스템 재시작 시 중복 처리를 방지하기 위해, Redis에 저장된 마지막 처리 Changelog Index를 로드하여 해당 지점부터 이벤트 수집을 재개합니다.
Lustre에서 수집되는 이벤트 타입은 내부적으로 두 개의 그룹으로 분류하여 처리합니다.
- create_modify
CREAT,MKDIR,CLOSE,TRUNC,SATTR,MTIME
- rename_delete
RMDIR,RENME,UNLINK
왜 Redis Stream인가?
실시간 DR 솔루션에서 이벤트 큐로 Redis Stream을 선택한 이유는 다음과 같습니다.
-
순서 보장의 중요성
실시간 동기화 환경에서는 이벤트가 발생한 순서대로 처리되는 것이 매우 중요합니다.
예를 들어, 파일 생성 → 수정 → 삭제 순서가 뒤바뀔 경우 데이터 불일치가 발생할 수 있습니다.
Redis Stream은 시간 순으로 정렬된 로그 구조를 제공하여, 이벤트의 순차적 처리를 보장합니다. -
빈번한 이벤트 처리 성능
대규모 Lustre 파일시스템 환경에서는 초당 수천 건 이상의 파일 변경 이벤트가 발생할 수 있습니다.
Redis Stream은 메모리 기반의 고성능 데이터 구조로, 이러한 빈번한 이벤트를 빠르게 수집하고 처리할 수 있습니다. -
대량 이벤트 저장 및 관리
파일시스템 변경 이벤트는 지속적으로 누적되며, 동기화 처리 지연 시 대량의 이벤트가 일시적으로 적재될 수 있습니다.
Redis Stream은 수백만 건 이상의 엔트리를 효율적으로 저장·관리할 수 있어, 피크 시간대의 이벤트 폭주 상황에서도 안정적인 처리가 가능합니다. -
Consumer Group을 통한 안전한 이벤트 처리
Redis Stream의 Consumer Group 기능을 활용하면, 여러 소비자가 동일한 스트림을 안전하게 읽고 처리할 수 있습니다.
이를 통해 이벤트의 중복 처리나 누락 없이, 작업을 여러 소비자에게 분산할 수 있습니다. -
비동기 처리 및 버퍼링
이벤트를 수집하는 모니터링 컴포넌트와 이를 처리하는 소스 서버 컴포넌트 간에는 처리 속도 차이가 발생할 수 있습니다.
Redis Stream은 이러한 속도 차이를 효과적으로 버퍼링하여, 이벤트 손실 없는 안정적인 비동기 처리 구조를 제공합니다.
Redis Stream 구조
수집된 이벤트는 처리 목적과 동기화 방식에 따라 여러 개의 Redis Stream으로 분리하여 관리됩니다. 이를 통해 이벤트 처리 흐름을 명확히 구분하고, 동기화 실패 시에도 효율적으로 재처리할 수 있도록 설계했습니다.
-
원본 이벤트 스트림
Lustre Changelog를 통해 수집한 파일 생성, 수정, 삭제 등의 이벤트를 가공 없이 그대로 저장하는 스트림입니다. -
rsync 동기화 이벤트 스트림
원본 이벤트 스트림(1)에서 선별된 이벤트 중 rsync 기반 동기화 대상 이벤트 그룹을 저장하는 스트림입니다. -
gRPC 동기화 이벤트 스트림
원본 이벤트 스트림(1)에서 선별된 이벤트 중 gRPC 기반 동기화 대상 이벤트 그룹을 저장하는 스트림입니다. -
rsync 재동기화 이벤트 스트림
rsync 동기화 이벤트 스트림(2)에서 동기화에 실패한 이벤트 중 재처리가 필요한 이벤트를 저장하는 스트림입니다. -
gRPC 재동기화 이벤트 스트림
gRPC 동기화 이벤트 스트림(3)에서 동기화에 실패한 이벤트 중 재처리가 필요한 이벤트를 저장하는 스트림입니다.
전체 구조 요약
- event: 이벤트 타입 (CREATE, MODIFY, MKDIR, DELETE, RENAME)
- path: 파일/디렉토리 절대 경로 (RENAME 시 원본 경로)
- to_path: RENME 이벤트 시 변경될 경로
- mdt: MDT 이름
- index: Lustre Changelog index
Redis
│
├── Streams (Redis Stream)
│ ├── rsync 동기화 이벤트 스트림
│ │ └── Entry: {event, path, mdt, index}
│ │
│ ├── gRPC 동기화 이벤트 스트림
│ │ └── Entry: {event, path, to_path, mdt, index}
│ │
│ ├── 원본 이벤트 스트림
│ │ └── Entry: {event, path, mdt, index}
│ │
│ ├── rsync 재동기화 이벤트 스트림
│ │ └── Entry: {event, path, mdt, index}
│ │
│ └── gRPC 재동기화 이벤트 스트림
│ └── Entry: {event, path, to_path, mdt, index}
│
├── Checkpoints (String)
│ ├── 마지막 처리된 rsync 동기화 이벤트 스트림 ID를 저장하는 Hash
│ │ └── Value: "1234567890124-0"
│ │
│ └── 마지막 처리된 gRPC 동기화 이벤트 스트림 ID를 저장하는 Hash
│ └── Value: "1234567890126-0"
│
└── Indexes (String)
├── 마지막 처리 이벤트의 Lustre Changelog Index를 저장하는 Hash
└── Value: "12350"
1. 원본 이벤트 스트림 구조
┌─────────────────────────────────────────────────────────────┐
│ Entry ID: 1234567890123-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "CREATE" │ │
│ │ path │ "/lustre/file.txt" │ │
│ │ mdt │ "MDT0000" │ │
│ │ index │ "12345" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
2. rsync 동기화 이벤트 스트림 구조
┌─────────────────────────────────────────────────────────────┐
│ Entry ID: 1234567890123-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "CREATE" / "MODIFY" / "MKDIR" │ │
│ │ path │ "/lustre/file.txt" │ │
│ │ mdt │ "MDT0000" │ │
│ │ index │ "12345" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ Entry ID: 1234567890124-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "MODIFY" │ │
│ │ path │ "/lustre/file2.txt" │ │
│ │ mdt │ "MDT0001" │ │
│ │ index │ "12346" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
3. gRPC 동기화 이벤트 스트림 구조
┌─────────────────────────────────────────────────────────────┐
│ Entry ID: 1234567890125-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "RENAME" │ │
│ │ path │ "/lustre/old.txt" │ │
│ │ to_path │ "/lustre/new.txt" │ │
│ │ mdt │ "MDT0000" │ │
│ │ index │ "12347" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ Entry ID: 1234567890126-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ |
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "DELETE" │ │
│ │ path │ "/lustre/file.txt" │ │
│ │ to_path │ "" │ │
│ │ mdt │ "MDT0000" │ │
│ │ index │ "12348" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
4. rsync 재동기화 이벤트 스트림
┌─────────────────────────────────────────────────────────────┐
│ Entry ID: 1234567890127-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "CREATE" │ │
│ │ path │ "/lustre/retry_file.txt" │ │
│ │ mdt │ "MDT0000" │ │
│ │ index │ "12349" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
5. gRPC 재동기화 이벤트 스트림
┌─────────────────────────────────────────────────────────────┐
│ Entry ID: 1234567890128-0 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Field │ Value │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ event │ "RENAME" │ │
│ │ path │ "/lustre/old_retry.txt" │ │
│ │ to_path │ "/lustre/new_retry.txt" │ │
│ │ mdt │ "MDT0000" │ │
│ │ index │ "12350" │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
2. 동기화 처리 단계
소스 서버 컴포넌트는 Redis Stream에서 이벤트를 읽어 이벤트 타입에 따라 적절한 동기화 방법을 선택하여 처리합니다.
동기화는 이벤트 타입에 따라 두 가지 방식으로 나뉩니다:
rsync를 통한 동기화
파일 생성이나 수정 이벤트의 경우, 대용량 데이터 전송에 최적화된 rsync를 사용합니다. 소스 서버 컴포넌트는 변경된 파일 목록을 수집하고, SSH를 통해 타겟 서버로 파일을 복사합니다. 이 방식은 파일의 실제 데이터를 효율적으로 전송하는 데 적합합니다.
동기화 과정은 다음과 같이 진행됩니다:
- 이벤트 수집: Redis Stream의 rsync 동기화 스트림에서 배치 크기만큼 가져와서 동기화 파일 목록을 생성합니다.
- 파일 존재 확인: 각 파일의 존재 여부를 사전 확인하여 존재하지 않는 파일은 동기화 파일 목록에서 제거합니다.
- 임시 파일 생성: 존재하는 파일들의 상대 경로를 rsync 동기화에 사용할 임시 파일에 추가합니다.
- rsync 실행: 생성된 임시 파일을 이용하여 rsync 동기화를 실행합니다.
- 결과 확인: rsync 실행 후 실패 파일, 추가 변경 파일을 확인하여 재동기화가 필요한 파일들은 재동기화 스트림에 저장합니다.
- Index 업데이트: 동기화 완료 후 Changelog Index를 업데이트합니다.
gRPC를 통한 동기화
파일명 변경이나 삭제 이벤트의 경우, gRPC를 통해 타겟 서버 컴포넌트에 직접 요청합니다.
타겟 서버 컴포넌트는 gRPC 요청을 받아 파일 이동, 삭제 등의 작업을 수행하며, 소스 서버와 타겟 서버 간의 경로 차이를 자동으로 변환하여 올바른 위치에 동기화합니다.
gRPC를 통한 동기화 과정은 다음과 같습니다:
- 이벤트 수집: Redis Stream의 gRPC 동기화 스트림에서 배치 크기만큼 가져와서 동기화 파일 목록을 생성합니다.
- gRPC 요청 전송: 타겟 서버의 API를 호출하여 작업을 수행합니다.
- 파일 작업 실행: 타겟 서버에서 파일 이동 또는 삭제를 수행합니다.
- 결과 반환: 성공/실패 여부와 상세 오류 정보를 소스 서버에 반환합니다.
- 결과 확인: 실패 파일 목록 중에서 재동기화가 필요한 파일들을 재동기화 스트림에 저장합니다.
- Index 업데이트: 성공한 작업에 대해서만 Changelog Index를 업데이트합니다.
3. 이벤트 처리 상태 관리
시스템 재시작이나 예기치 않은 장애 상황에서도 이벤트의 중복 처리나 누락을 방지하기 위해, 글루시스 DR 솔루션은 이벤트 처리 상태를 체계적으로 추적·관리합니다. 이를 위해 두 가지 레벨의 상태 관리 메커니즘을 적용하여, 수집 단계부터 동기화 단계까지 안정적인 처리가 가능하도록 설계했습니다.
MDT별 Changelog Index 관리
각 MDT에서 마지막으로 처리된 Changelog Index는 Redis에 해시(Hash) 형태로 저장되며, 해당 값은 MDT별로 독립적으로 관리됩니다.
모니터링 컴포넌트는 시작 시 Redis에 저장된 각 MDT의 마지막 Changelog Index를 로드한 뒤, 해당 지점 이후부터 Changelog를 읽기 시작합니다. 예를 들어 MDT0000의 마지막 처리 Index가 12350인 경우, 다음 이벤트인 12351부터 Changelog를 읽어 이벤트 수집을 재개합니다.
이와 같은 방식으로 동작함으로써, 시스템이 예기치 않게 종료되더라도 각 MDT별로 정확한 처리 지점부터 이벤트 수집을 재개할 수 있어, 중복 처리나 이벤트 누락 없이 안정적인 모니터링이 가능합니다.
동기화 인덱스 관리
소스 서버 컴포넌트는 Redis Stream에서 이벤트를 읽어 처리할 때, 마지막으로 처리된 Stream Entry ID를 체크포인트로 저장합니다.
동기화 작업이 완료될 때마다 체크포인트는 갱신되며, 다음 동기화 작업 시 이 체크포인트 이후의 이벤트만 읽어 처리합니다.
이를 통해 동기화 작업 중 장애가 발생하더라도, 재시작 시 이전에 처리된 이벤트를 다시 처리하지 않고 정확한 지점부터 동기화를 재개할 수 있습니다.
4. 예상치 못한 종료 시 복구 메커니즘
시스템 크래시, 네트워크 장애, 프로세스 강제 종료와 같은 예상치 못한 상황으로 프로그램이 중단되더라도, 사전에 저장된 인덱스 정보를 활용하여 이전 작업을 이어서 수행할 수 있도록 복구 메커니즘을 설계했습니다.
-
모니터링 컴포넌트 재시작
MDT별로 저장된 인덱스를 로드하여, 마지막으로 처리된 Changelog Index 이후의 이벤트만 수집합니다.
이미 수집되어 Redis Stream에 저장된 이벤트는 다시 저장되지 않으므로, 이벤트 중복 수집이 발생하지 않습니다. -
소스 서버 컴포넌트 재시작
Redis Stream에 저장된 동기화 체크포인트(Stream Entry ID) 를 로드하여, 마지막으로 처리된 Entry ID 이후의 이벤트만 읽어 처리합니다.
동기화가 완료되지 않은 이벤트는 자동으로 재처리되어, 작업의 연속성이 보장됩니다. -
타겟 서버 컴포넌트 재시작
gRPC 서버가 재시작되더라도, 소스 서버에서 재시도 요청을 전달하면 해당 요청을 정상적으로 처리할 수 있도록 설계되어 있습니다.
이와 같은 이중 인덱스 관리 구조(MDT별 Changelog Index + Redis Stream 체크포인트) 를 통해, 시스템이 어떤 단계에서 중단되더라도 정확한 처리 지점부터 이벤트 수집과 동기화를 재개할 수 있습니다.
이를 통해 중복 처리나 이벤트 누락 없이, 안정적인 DR 동작을 보장합니다.
5. 오류 처리 및 재시도 메커니즘
동기화 과정에서 발생하는 오류를 효율적으로 처리하기 위해 재시도 메커니즘을 구현했습니다.
동기화에 실패한 파일 목록을 분석하여, 재시도 가능한 오류와 재시도 불가능한 오류를 구분합니다.
재시도 스트림을 통한 누락 방지
동기화 과정에서 실패한 이벤트는 재시도 가능 여부를 판단하여 적절히 처리됩니다.
재시도 가능한 오류(일시적인 네트워크 오류, 파일 잠금, 타임아웃 등)는 rsync 재동기화 스트림과 gRPC 재동기화 스트림에 저장됩니다.
다음 동기화 작업 시 일반 스트림과 재동기화 스트림의 이벤트를 함께 처리하여, 일시적인 문제로 실패한 파일들도 정상적으로 동기화됩니다.
재동기화 스트림의 이벤트도 동일한 체크포인트 메커니즘을 통해 관리되므로, 재동기화 과정에서도 중복 처리가 발생하지 않습니다.
재시도 불가능한 오류 처리
재시도 불가능한 오류(예: 파일이 존재하지 않음, 권한 오류 등)는 상세한 오류 정보와 함께 로그에 기록되어 관리자가 수동으로 처리할 수 있도록 합니다.
각 실패 이벤트에는 오류 메시지, 오류 코드, 재시도 가능 여부 등의 정보가 포함되어 있어 문제 진단이 용이합니다.
DR 솔루션 등급 기준 및 시장 요구사항
아래 표는 시장에서 일반적으로 요구되는 재해 복구(DR) 솔루션의 등급 기준을 정리한 것입니다.
본 기준은 RPO(Recovery Point Object)와 RTO(Recovery Time Object)6를 포함한 복구 목표 수준에 따라 업무 중요도를 구분하며,
이후 글루시스 DR 솔루션의 테스트 결과를 해당 기준에 대입하여 등급을 평가합니다.
| 구분 | Platinum | Gold | Silver | Bronze |
|---|---|---|---|---|
| 대상 업무 | 기업의 생산, 판매 및 영업활동에 직접적인 영향을 주는 업무 | 기업의 대고객 서비스에 영향을 주는 업무 | 기업의 내부 운영에 영향을 주는 업무 | 기업의 내부 업무 지원을 위한 개발, 테스트 업무 |
| RPO | 0에 근접 | 0에 근접 | < 2일 | < 2일 |
| RTO | < 3시간 | < 24시간 | < 7일 | < 30일 |
| 권장 거리 | 근거리 + 장거리 | 근거리, 장거리 | 근거리, 장거리 | 근거리, 장거리 |
| 권장 DR 형태 | ≤ 3 x 데이터센터 | 2 x 데이터센터 | 2 x 데이터센터 | 2 x 데이터센터 |
| 권장 DR 솔루션 | 디스크 복제 | 디스크 복제 | 소프트웨어 복제 | 소프트웨어 복제, 백업 |
| 업무 성능 저하 허용 여부 | 불가 | 불가 | 허용 | 허용 |
글루시스 DR 솔루션 테스트 결과
아래 표는 글루시스 DR 솔루션의 실제 테스트 결과를 정리한 것입니다.
본 솔루션은 동기화 시 파일을 개별 처리하지 않고, 여러 파일을 하나의 배치로 묶어 처리하는 배치 기반 동기화 방식을 사용합니다.
- 동기화 평균 시간: 배치(파일 300개 기준)에 포함된 파일들을 실제로 동기화하는 데 소요된 시간
- 배치 대기 시간: 파일 변경을 감지한 시점부터 동기화가 시작되기까지의 대기 시간
| 구분 | 파일 평균 사이즈 | 파일 수 | 처리 속도 | 동기화 평균 시간 (배치당 300개 파일 기준) | 배치 대기 시간 |
|---|---|---|---|---|---|
| 큰 파일 | 55MB | 10,000 | 412 MB/s | 39s | 19m 40s |
| 작은 파일 | 314KB | 10,000 | 24.2 MB/s | 0.32s | 2m 42s |
테스트 결과 기반 RPO / RTO 평가
파일 동기화는 재해 복구 과정에서 가장 먼저 안정적으로 동작해야 하는 핵심 단계입니다.
테스트 결과를 살펴보면, 글루시스 DR 솔루션은 데이터 변경을 실시간으로 감지하고 배치 단위로 동기화를 수행하여, 아래와 같은 시간 내에 동기화가 완료되는 것을 확인할 수 있습니다.
- 작은 파일 중심의 업무 환경에서는 약 3분 이내
- 대용량 파일이 주로 생성되는 업무 환경에서도 약 20분 이내
이는 장애 발생 시 데이터 손실이 거의 발생하지 않는 수준으로, 실질적인 RPO가 0에 가깝게 유지됨을 의미합니다.
RTO는 기업의 시스템 구성과 운영 환경에 따라 차이가 있을 수 있으나, 실제 운영 시나리오를 기준으로 볼 때 수 시간에서 최대 하루 이내에 서비스 복구가 가능한 수준으로 판단됩니다.
앞서 정리한 시장 요구사항 등급 기준과 비교해보면, 글루시스 DR 솔루션은 Platinum 또는 Gold 등급 수준의 요구사항을 충족하는 DR 솔루션에 해당한다고 볼 수 있습니다.
마치며
이번 글에서는 대규모 Lustre 환경에서 전통적인 rsync 기반 DR 방식이 갖는 한계를 짚어보고, Lustre Changelog를 활용해 변경 이벤트를 추적·동기화하는 글루시스 DR 솔루션의 구조와 동작 원리를 소개했습니다. 또한 테스트 결과를 통해 배치 기반 동기화 환경에서도 RPO를 낮게 유지할 수 있음을 확인했습니다.
다음 글에서는 ZFS의 스냅샷/복제 기능을 활용한 DR 방식과 Lustre 기반 접근 방식의 차이점을 비교해보겠습니다.
각주
-
RPO : 재해 복구에서 허용 가능한 최대 데이터 손실 시간 ↩
-
Changelog : https://doc.lustre.org/lustre_manual.xhtml#lustre_changelogs ↩
-
rsync : Unix/Linux 시스템에서 파일과 디렉토리를 효율적으로 동기화하는 유틸리티 - https://rsync.samba.org/ ↩
-
Redis Stream : Redis 5.0에서 도입된 데이터 구조로, 시간 순서대로 정렬된 로그 형태의 메시지 큐 - https://redis.io/docs/data-types/streams/ ↩
-
gRPC : Google에서 개발한 고성능 오픈소스 RPC 프레임워크 - https://grpc.io/ ↩
-
RTO : 업무의 복구 목표 시간 ↩